
1、为什么要做外表刷新
StarRocks(简称 SR) 具备通过创建外表的方式来查询 hive 数据。SR fe 在生成查询计划时需要从 hive metastore 读取对应 hive 表、分区的元数据,为了获得更快的查询时效,SR 将已获取的 hive 元数据缓存在了 Fe 的内存中(使用 Guava LoadingCache 实现),从而减少对 hive metastore 的请求次数。
这样就产生一个问题,hive 表元数据变更时导致和 SR 缓存的元数据不一致,从而导致 SR 查询异常。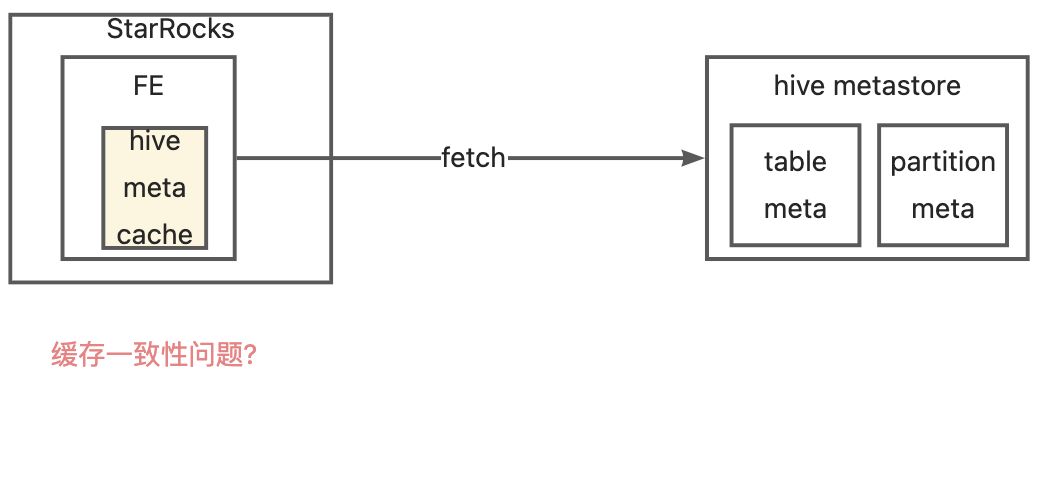
为了保持缓存元数据和 hive metastore 一致,SR 提供了两种刷新机制
- 自动刷新,也有 2 种方式
- 设置“缓存过期时间”或者“缓存自动刷新间隔时间”
- 自动增量更新元数据缓存,主要是通过定期消费Hive Metastore的 event 来实现,需要 hive 版本 > 3.1.2(待验证)
- 主动刷新,主动执行刷新 sql 来强制更新 SR 缓存的某张表的元数据,有2个操作
- refresh external table xxx 来更新级别的表的信息
- refresh external table xxx partion(yyy) 来更新缓存的分区的信息
因为所有 hive 表不是同一个时间变更的,所以 1.a 无法适用,其次 hive 版本也不满足 1.b 的要求。所以我们选择了“手动刷新”的方式,在一张 hive 表变更后通过系统手动刷新该表在 SR 的元数据。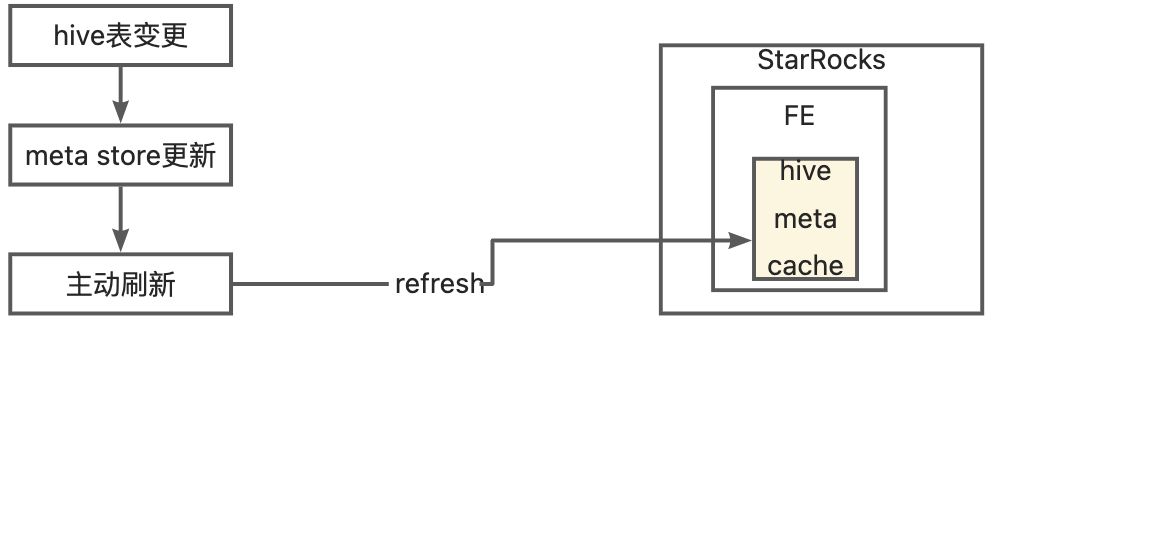
2、SR外表元数据的缓存设计
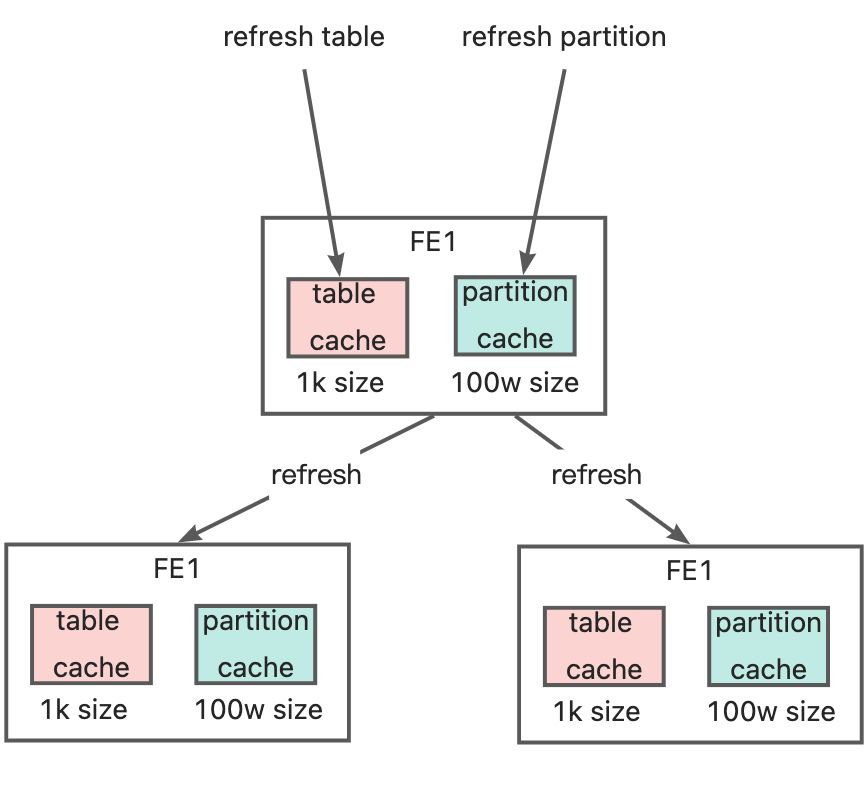
SR 对于 hive 元数据缓存在每个 Fe 内存中,适用 Guava LoadingCache 实现,共有 5 种(5个 loadingCache)缓存,可以分为两类
- 表级别缓存,缓存 size <=1k,即最多缓存 1k 张表的信息,超过按 LRU 策略置换;有 3 种
- partitionKeysCache:一个表中所有的分区信息
- tableStatsCache:表数据的信息,如 numRows、totalFileBytes
- tableColumnStatsCache:字段信息,如字段类型、字段的最大最小值等
- 分区级别缓存,缓存** size <=100w**,即最多缓存 100w 个分区的信息,超过按 LRU 策略置换;有 2 种
- partitionsCache:一个分区对应的底层文件信息,如 hdfs 目录
- partitionStatsCache:一个分区的说句信息,如 numRows、totalFileBytes
1
2
3
4
5
6
7
8
9
10
11
12
13
14// HivePartitionKeysKey => ImmutableMap<PartitionKey -> PartitionId>
// for unPartitioned table, partition map is: ImmutableMap<>.of(new PartitionKey(), PartitionId)
LoadingCache<HivePartitionKeysKey, ImmutableMap<PartitionKey, Long>> partitionKeysCache;
// HivePartitionKey => Partitions
LoadingCache<HivePartitionKey, HivePartition> partitionsCache;
// statistic cache
// HiveTableKey => HiveTableStatistic
LoadingCache<HiveTableKey, HiveTableStats> tableStatsCache;
// HivePartitionKey => PartitionStatistic
LoadingCache<HivePartitionKey, HivePartitionStats> partitionStatsCache;
// HiveTableColumnsKey => ImmutableMap<ColumnName -> HiveColumnStats>
LoadingCache<HiveTableColumnsKey, ImmutableMap<String, HiveColumnStats>> tableColumnStatsCache;
2 类缓分别有其对应的刷新动作,连接某台 fe 执行刷新动作时,SR 会在所有 fe 上执行缓存刷新操作
sql: refresh external table xxx刷新表级缓存信息sql: refresh external table xxx partition(yyy)刷新分区级缓存信息
3、缓存相关流程和存在的问题
3.1、缓存使用的流程
如 之中所述,使用hive 外表时需要创建 hive resource,它和缓存的关系如图:
- ResourceMgr 管理所有 resource
- HiveRepository 中管理每个 resource 对应的 HiveMetaCache
- HiveMetaCache 依赖 Resource 而存在,如果 Resource 被删,HiveRepository 会清除对应的 HiveMetaCache
在 SR 查询 sql 生成执行计划时,会通过 catalog 调用 HiveRepository 查询对应 resource 的元数据缓存,如果缓存信息缺乏,会即时的去 hiveMetaStore 获取并更新缓存;
3.2、主动刷新动作的执行流程
刷新动作执行的整体流程:
- 刷新本 fe 缓存
- 成功后请求其他 fe 刷新缓存
- 其他 fe 刷新失败时也不会使本 fe 缓存回滚,所以这里可能存在 fe 之间缓存不一致的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public void refreshExternalTable(RefreshExternalTableStmt stmt) throws DdlException {
// 刷新本 fe 缓存
refreshExternalTable(stmt.getDbName(), stmt.getTableName(), stmt.getPartitions());
List<Frontend> allFrontends = Catalog.getCurrentCatalog().getFrontends(null);
Map<String, Future<TStatus>> resultMap = Maps.newHashMapWithExpectedSize(allFrontends.size() - 1);
for (Frontend fe : allFrontends) {
if (fe.getHost().equals(Catalog.getCurrentCatalog().getSelfNode().first)) {
continue;
}
resultMap.put(fe.getHost(), refreshOtherFesTable(new TNetworkAddress(fe.getHost(), fe.getRpcPort()),
stmt.getDbName(), stmt.getTableName(), stmt.getPartitions()));
}
// 成功后请求其他 fe 刷新缓存
String errMsg = "";
for (Map.Entry<String, Future<TStatus>> entry : resultMap.entrySet()) {
try {
TStatus status = entry.getValue().get();
if (status.getStatus_code() != TStatusCode.OK) {
String err = "refresh fe " + entry.getKey() + " failed: ";
if (status.getError_msgs() != null && status.getError_msgs().size() > 0) {
err += String.join(",", status.getError_msgs());
}
errMsg += err + ";";
}
} catch (Exception e) {
errMsg += "refresh fe " + entry.getKey() + " failed: " + e.getMessage();
}
}
if (!errMsg.equals("")) {
ErrorReport.reportDdlException(ErrorCode.ERROR_REFRESH_EXTERNAL_TABLE_FAILED, errMsg);
}
}
refresh external table xxx 刷新表级缓存信息流程:
refresh external table xxx partition(yyy) 刷新分区级缓存信息流程:同上,区别在于刷新失败不清除缓存。
3.3、我们的使用流程
- 缓存设为不失效和不自动更新
- 调度任务执行成功后触发刷新动作
- 先
refresh external table xxx刷新表级缓存信息 - 成功后执行
refresh external table xxx partition(yyy)刷新本任务新生成的分区信息
- 先
3.4、现有流程引发的问题
1)分区过多(如几十万)的表刷新访问 metastore 太慢,如 3.2 刷新表级缓存流程所述,会一直占有写锁,导致其他表的刷新动作一直等待获取锁直至 mysql client 连接超时或者获取不到新连接,缓存得不到刷新,查询不到最新的数据。
1 | public void refreshTable(HiveMetaStoreTableInfo hmsTable) |
2)补数任务执行刷新分区动作失败后,导致表级缓存和分区级缓存不一致,查询失败
表级刷新动作,会刷新 partitionKeysCache,所以它执行成功就有表中有哪些分区的信息,这时:
- 当是新增/删除分区时,即使刷新分区动作失败,fe 使用时也会自动加载对应分区信息所以不影响使用
- 当是更新已有分区时,已有分区信息若在分区信息partitionsCache缓存中,那刷新分区动作失败,fe 使用时候拿到的是旧缓存所以查询会异常。
这就是现在每天调度任务刷新多级分区失败但是不影响使用,补数时刷新多级分区失败导致查询异常的原因。
3)刷新表级缓存动作失败,但是不影响使用
原因就是如 3.2 中所述,表级刷新失败会导致清除该表的所有缓存,这样 fe 使用时会按需重新从 hive metastore 中加载,所以不影响使用
4、终级方案
无论用哪种方式,都是为了使 hive meta store 变更时,变更能及时同步到 sr 的缓存中,现有流程也是这么做的,只是做到到调度层。最好的方式可以下沉到 hive 层,对调度和用户透明。有 2 种方式可以实现,待探索
- 消费 hive metastore 的 binlog,触发对 sr 的刷新动作
- 使用 hive meta hook 机制来触发对 sr 的刷新动作

