
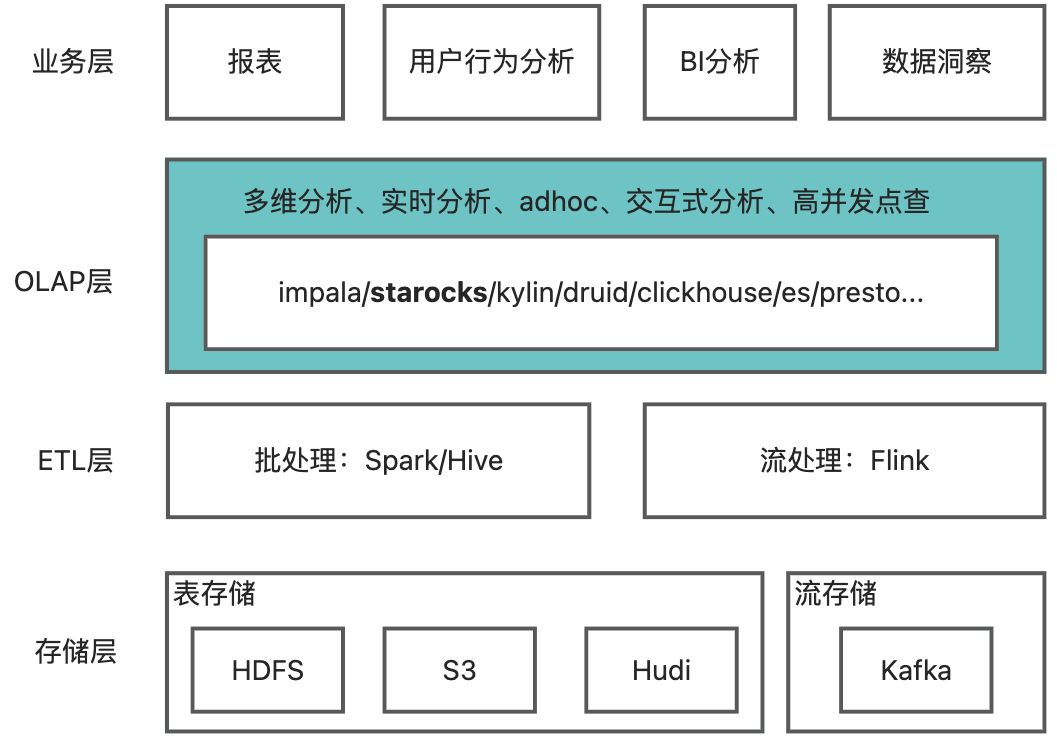
OLAP 场景介绍
一般来说,OLAP 层作为大数据体系的出口,直接服务于业务层,也可以说它面向的是人。所以虽然都是分布式计算引擎,但是它有别于 ETL 引擎:
- OLAP面向的是人,所以 OLAP 的核心要求是快速
- 报表等场景要求 2 - 5 秒内出数
- 点查要求毫秒出数
- ad-hoc、交互式分析可以容忍几十秒,但也是要秒级出数
- ETL 一般面向的是存储, 它的特点是“读取大量数据、长时间执行(秒-天级别)”。所以它的核心要求是:高稳定性、高容错性,毕竟重跑 ETL 代价太高。
- ETL 加工出结果数据后,通过 OLAP 引擎对外提供服务主要有 2 种查询方式:
- 相对固定的计算逻辑,如固定报表
- 不固定的计算逻辑,如交互式分析
如前所述,OLAP 面向的业务场景多样,对查询时间的要求不一而足,往往需要在在以下几个维度上去权衡
所以相较于 ETL 层 Spark 和 Flink 一统天下,OLAP 引擎可谓百花齐放[20]。整体来说可分 2 种:
- MOLAP(Multidimensional OLAP):关键技术是预计算,数据摄入 OLAP 引擎时提前聚合和结果(指标)数据,可做到超大数据量上的快速查询响应。所以主要是服务固定分析逻辑的场景,比如固定报表
- Kylin: 适配离线分析场景,导入 hive 数据
- Druid:适配实时分析场景,可以实时摄入数据、实时聚合。
- ROLAP(Relational OLAP):关键技术是现场计算,不进行预聚合,现场执行计算逻辑,适用于灵活复杂查询场景,比如交互式分析
- 因为要快,一般都采用 MPP 架构;
- 一种是只实现了计算引擎,分析外部数据比如 hive 的,所谓 SQL on hadoop。如 impala、presto
- 另一种是实现了存储和计算的 MPP 数据库,如 doris、starrocks、clickhouse 等
- 传统的 SQL 引擎如 spark sql/hive 也能服务 OLAP 场景,但是速度比较慢,一般不用他;
- 因为要快,一般都采用 MPP 架构;

但是随着发展,技术也在不断融合和统一,所以就有了 HOLAP(Hybrid OLAP),也就是融合了 MOLAP 和 ROLAP 的特点的引擎。我觉得 Doris/StarRocks 应该就属于这一种了,他支持“预聚合”、也支持“现场计算”。相较于其他 OLAP 引擎,能覆盖更多的场景。而 OLAP 引擎也是在向这个方向发展(个人意见)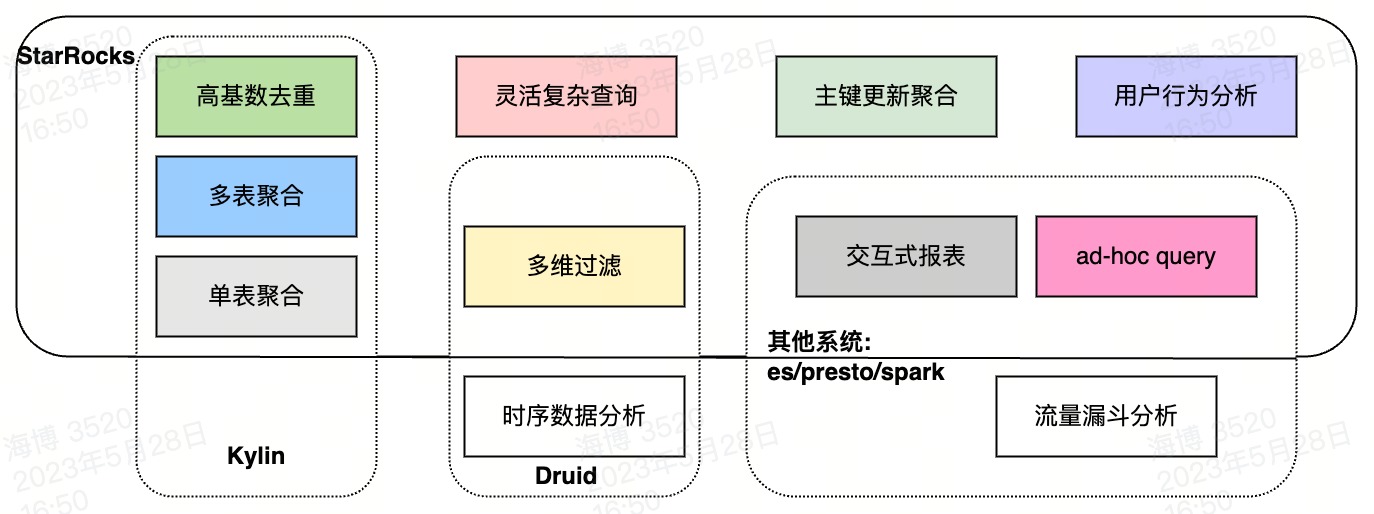
StarRocks 介绍
如前所述,OLAP 引擎的要求是快,而发展方向也是趋向于一个引擎覆盖多种场景。所以看看 StarRocks 给自己的定位:其实也是在强调这 2 点。
新一代“极速”、“全场景”MPP 数据库
发展史
- 起初是百度为了解决自己广告报表的问题[21],借鉴 Google Mesa、Apache impala、ORCFile 开发的系统。
- 存储部分:Data Model 借鉴了 Mesa[6],存储格式借鉴了 ORCFile,采用列式存储
- 计算部分:借鉴了 impala[7] 的实现,分为 FE、BE 2 种节点
- 成熟后贡献给 Apache,开源后改名 Doris。随后一波核心开发创业开发了 DorisDb,随后开源的 Doris 和 Doris DB 闹矛盾,于是
- DorisDB 改名为了 StarRocks 并进行了开源
- 而 Doris 自己也发布了商业版本 SelectDb

StarRocks RoadMap,关键技术
- 向量化引擎
- Primary Key 表
- Pipeline 引擎
- 数据湖分析
- 存算分离

架构
自成一体,开箱即用,不依赖其他大数据组建。整体结构借鉴 impala,分为 2 种节点:
- FE:java 实现,使用类 Raft 算法保证元数据一致性,所以 FE 节点数得是奇数
- 负责元数据管理:库表信息、存储信息等
- 负责管理客户端 JDBC 连接
- 负责接收 query、解析 query、生成执行计划和执行计划的调度
- BE:c++ 实现,数据多副本,保证数据不丢,是个 CP 系统(牺牲可用性来保证数据强一致性)
- 负责数据读写、存储
- 负责执行 FE 下发的计算任务

存储部分
查询要快,离不开存储方面的支持:
- 自建存储,存储计算一体化,减少网络 IO
- 自建列存格式和多级索引,减少数据扫描量
- 聚合表模型、物化视图等,可以实现数据的实时预聚合,减少查询时的计算量
数据格式
存储结构由 4 层组成:partition、tablet、rowset、segment。
Segment File(类似 SSTable) 是真正的数据文件,是一个“类 parquet” 的列存储格式(OLAP 数据库都是列存)。整体的文件格式分为数据区域,索引区域和 footer 三个部分,如下图所示:
数据模型
存储部分借鉴了 Google Mesa 。Mesa 是一个分析型的数据仓库系统(highly scalable analytic data warehousing system),主要用于谷歌的广告业务(分析、报表)中。它非常强调“实时性”,它要支持:
- Near Real-Time Update Throughput :实时的大批量的数据更新
- 实时更新:must support continuous updates
- tps 达到几百万:millions of rows updated per second
- Query Performance:point query 的 p99 要达到几百毫秒,就是要满足这种低时延的场景
- Atomic Update
- Consistency and Correctness,所以 StarRocks 是一个 CP 系统,保证数据的强一致性
- Online Data and Metadata Transformation
为了实现“实时分析”,Mesa 设计了“聚合表模型”,可以在随着数据更新实时更新聚合结果,如图所示
- 如左边所示,表 schema 字段分为维度和指标。最终数据会根据维度 date、publishId、Country 聚合(这里聚合函数是 sum)出指标值 clicks、cost
- 如右边所示,当有明细数据不断导入时,会自动更新聚合后的结果
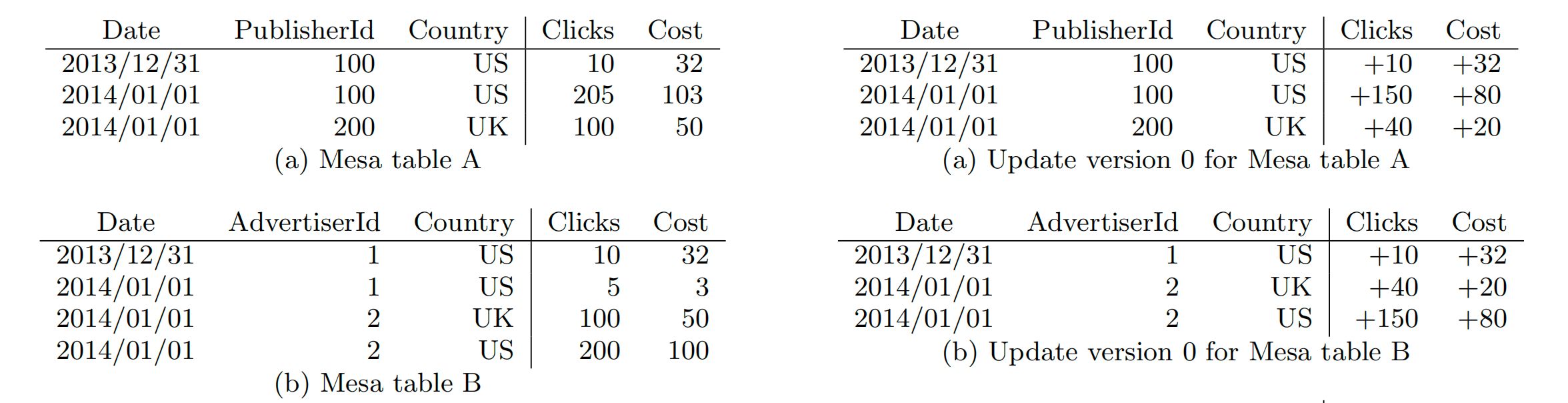
那这种预聚合是怎么实现的呢[8]
- 采用了多数据版本,每个写入批次会生成一个数据版本,利用这种方式实现了 Atomic Update 和 snapshot isolation
- 后台会不断通过 2 级 compaction 的方式:base compaction、cumulative compaction 来对多个版本的数据进行合并
- 查询时,如果没有 compaction 完成,会临时进行数据的聚合,即 merge on read

这种实现的好处是:
- 类 lsm Tree 的写入方式,保证了支持大批量的写入吞吐
- 2 级 compaction 方式的思想是,将查询时的 merge on read 时长分摊到了一个比较长的时间轴上。进而保证较低的查询时延。所以,compaction 的机制设计非常重要,如何不合理,就会导致查询时延无法保证。
题外话:为什么不建议用 insert into 导入大量数据呢,就是因为一个 insert 语句就会生成一个数据版本,100w 个 insert 语句就生成 100w 个数据版本需要后台 compaction,这远远超过了 compaction 的能力。
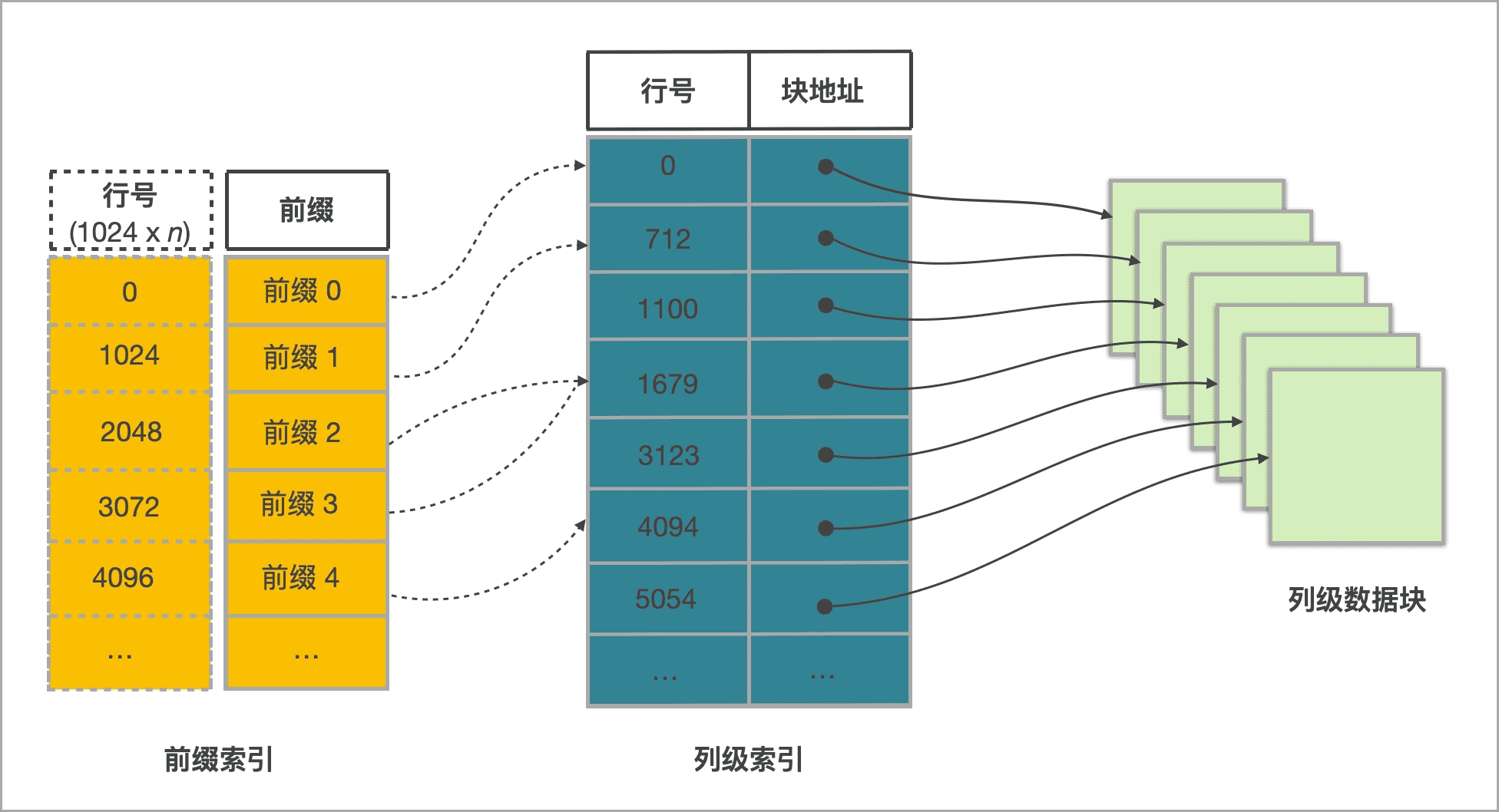
数据索引
索引有前缀索引和列级索引[17]:
- 前缀索引:系统创建,使用表中某行数据的维度列所构成的前缀查找前缀索引表,可以确定该行数据所在逻辑数据块的起始行号。
- 列级索引[18]:
- 行号索引:系统创建,使用行号索引可以找到列级数据块(表中每列数据都按 64 KB 分块存储。)
- ZoneMap 索引:系统创建,存储一列的 max、min 等信息
- BloomFilter 索引:用户自己创建,快速过滤某个 data page 是否包含某个值
- Bitmap 索引:用户自己创建,能够提高指定列的查询效率,适用于低基数的列
计算部分
在计算部分 StarRocks 通过以下措施,进而达到极致的查询性能,本篇重点介绍下执行阶段。
- 执行规划阶段:
- CBO,生成一个 “最佳的”(执行 Cost 最低)的分布式物理执行计划
- Join 分布式执行策略选择
- 低基数字典优化
- Global Runtime Filter 下推
- 执行阶段:
- MPP 多机并行机制来**充分利用多机的资源 **
- 通过 Pipeline 并行机制来充分利用单机上多核的资源
- 通过向量化执行来充分利用单核的资源,进而达到极致的查询性能
- cache:
- page cache,数据库层面的文件缓存
- query cache,数据库层面的查询结果缓存
执行流程
查询的执行步骤[10]和 spark sql[9] 执行流程类似:
- Query Parsing: SQL 先解析为 AST,这里和 spark sql 一样使用了 Antlr4
- Query analysis: 基于 AST 检查绑定 db、tb、clumn 等愿信息,并检查 SQL 的合法性
- Query Planing: 将 AST 转为 Logical Plan (Single node plan,不能真正的被分布式调度执行)
- Query Optimize: Logical Plan 经过 CBO 优化器生成 physical plan (分布式执行计划)
- physical plan 按照 exchange boundaries (shuffle 边界) 进行切分,切分为 plan fragment, A plan fragment encapsulates a portion of the plan tree that operates on the same data partition on a single machine. 就是类似 spark 通过宽依赖和窄依赖切分为 stage。

Query Analyze -> Logical Plan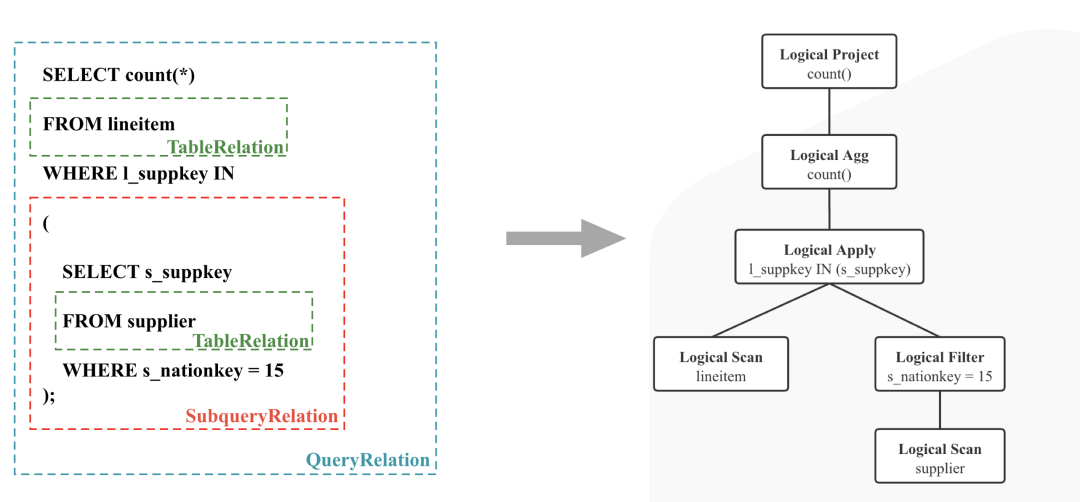
Optimizer(CBO):
StarRocks Optimizer 的输入是一棵逻辑计划树,输出是一棵 Cost “最低” 的分布式物理计划树。
StarRocks 优化器完全自研,主要基于** Cascades 和 ORCA 论文**实现,并结合 StarRocks 执行器和调度器进行了深度定制,优化和创新。
举个例子:比如下推、比如 join 策略的选择。比如这个 impala 的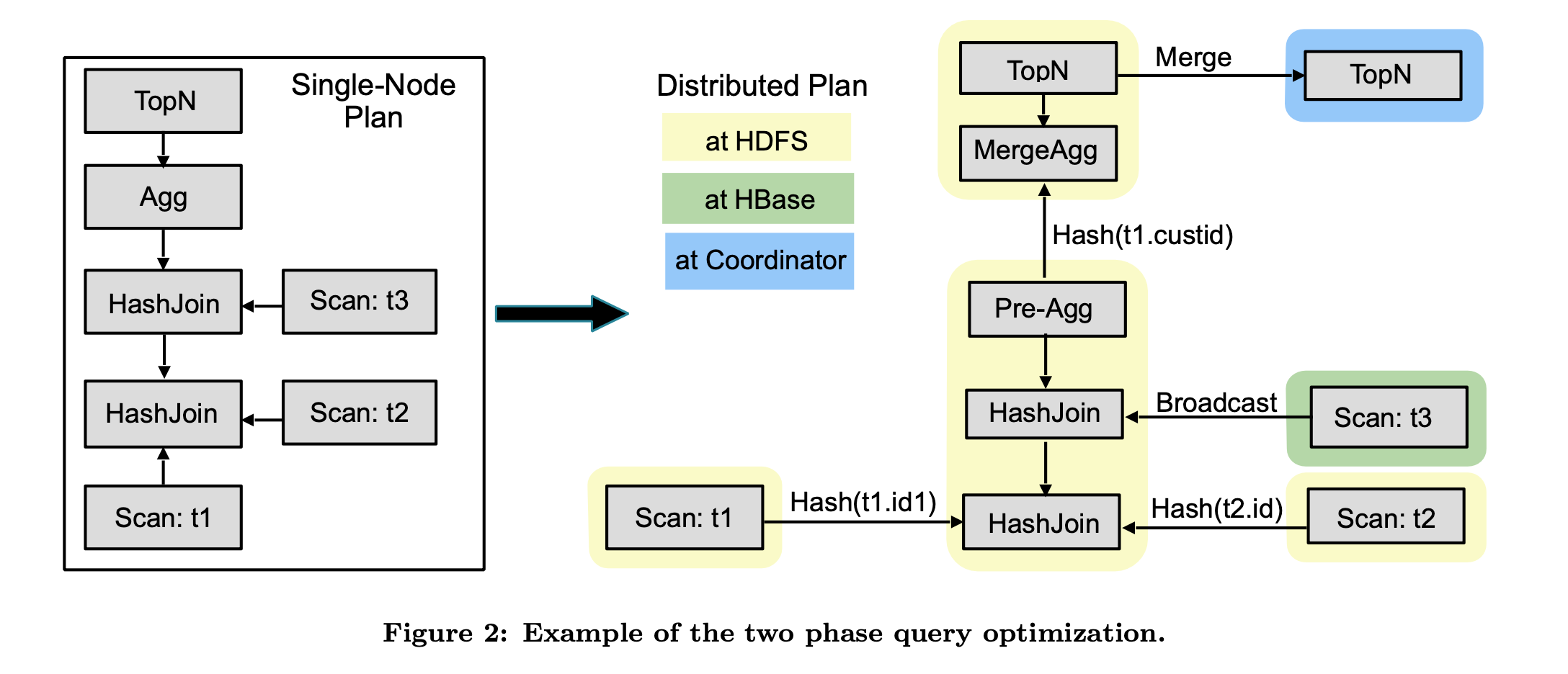
MPP 执行
MPP 全称 Massive Parallel Processing(如图,sharde nothing 架构),个人理解,这是概念主要是和 SMP、NUMP 做区分;在大数据领域,这个概念变得模糊,其实我认为 Spark 也是 MPP 的结构,或者说大数据处理引擎就没有不是 MPP 的[11]。
回到 StarRocks
- 一个 Fragment 可以有多个实例,分布在多个 BE 节点上同时执行(同理,saprk 的 1 个 stage 可以有多个 task)
- 单个 Fragment 实例的并行度可以调整(同理,spark 可以通过调整 shuffle partitions 调整 task 并行度)
- 对于 Scan 操作的 Fragment 需要考虑 data locality。回顾存储部分内容,数据是被分捅(tablet)存储的,每个 tablet 又会有多个 replica,所以:
- 1)Scan 可以并行,每个 tablet 可以对应一个 Fragment Instance
- 2)由于一个 tablet 多副本,所以 Fragment Instance 可以调度到压力较低的 BE 上
- 对于非 Scan 操作,可以调度到压力比较小的 BE 节点上执行,总体上调度器会保证每个 BE 节点上的负载均衡。

但有几点不同:
- 资源常驻,不需要向一个共享的比如 yarn 去申请,这样会拖慢查询时效
- 多个 Fragment 之间会以 Pipeline 的方式在内存中并行执行,而不是像批处理引擎那样 Stage By Stage 执行。

Pipeline
注意:这里的 pipeline 不是“MPP 执行”中所述的 pipeline。这里的 Pipeline 指的是单台 BE 上的调度执行框架。那么为什么需要它呢。
如上所述,在 MPP 执行框架中:
- SQL 被拆分为 Fragment 后,Fragment Instance 会被调度到 BE 上去执行。
- 在单台 BE 上,Fragment Instance 得调度比较简单。一个 Fragment Instance 就是生成一个线程去执行。

但是这种方式存在一定的问题:
- 大量的查询会生成大量的 Fragment Instance, 又会单台 BE 上生成大量的线程。
- 这些 Fragment Instance 中的 Operator 操作如果包含 IO 操作,如 scan、shuffle,又会导致线程挂起。
- 于是,这种方式在单台 BE 上,会让操作系统进行频繁的线程创建、调度、销毁,而这需要操作系统频繁的在内核态和用户态之间去切换。从而让 cpu 的能力没有充分的用于执行计算逻辑上。
为了解决这个问题,开发了 Pipeline 并行执行框架[12]:
- Pipeline 框架的核心是实现一个用户态的协程调度,不再依赖操作系统的内核态线程调度,减少线程创建、线程销毁、线程上下文切换的成本。
- 实现形式上,它是一个多级反馈队列(比较类似 os 的线程调度模式):StarRocks 会启动机器 CPU 核数个执行线程,每个执行线程会从一个多级反馈就绪队列中获取 Ready 状态的 Pipeline 去执行。
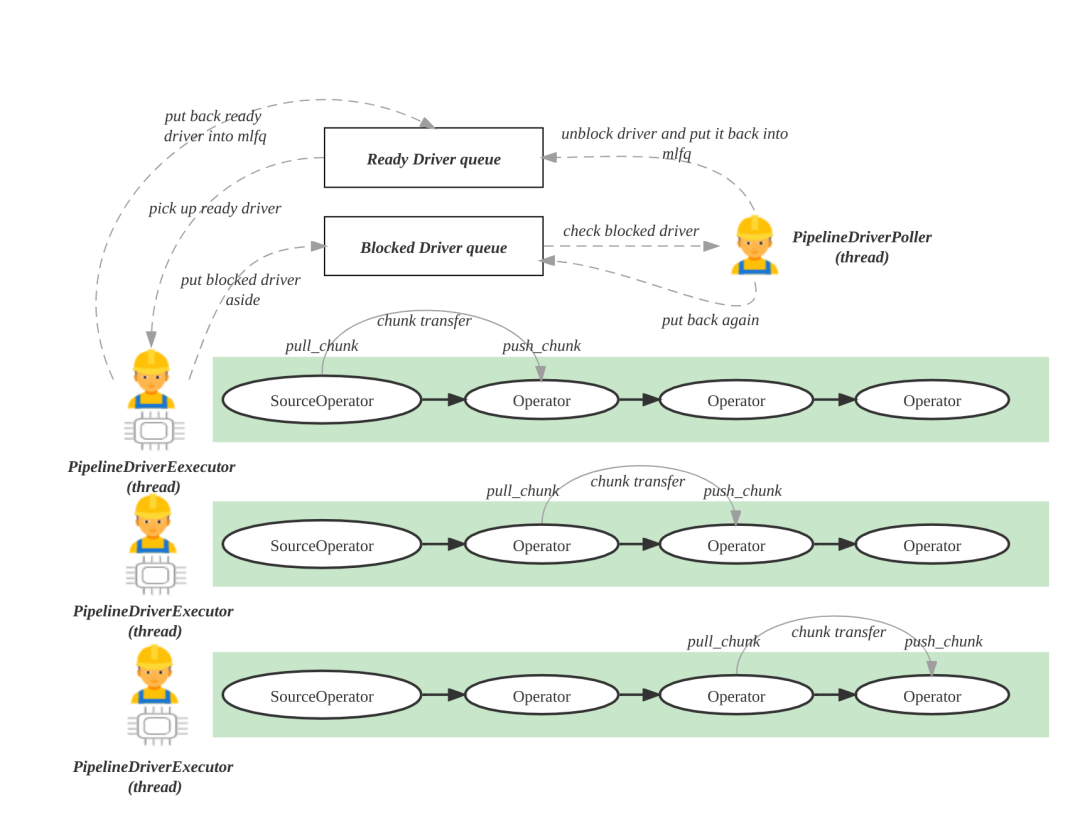
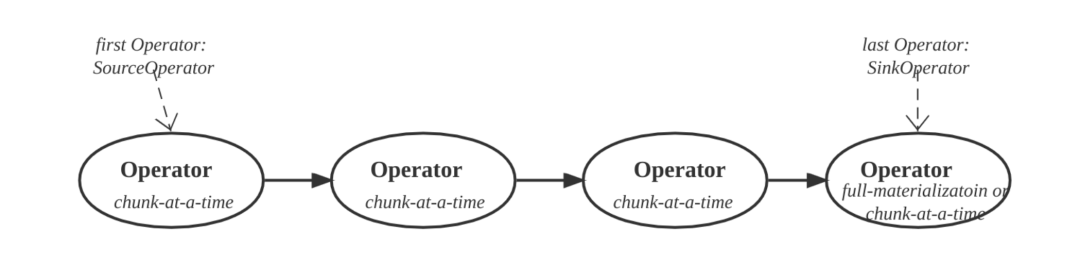
而 Pipeline 就是被调度的单位,它就是一组算子构成的链,开始算子为 SourceOperator,末尾算子为 SinkOperator。它是由 Fragment 拆分而来,资源隔离能力的 cpu 隔离也是在这个层面去做的。
向量化
随着计算机技术的发展,cpu 对指令集的支持也在不断的发展。首先我们主要了解这 2 种指令集[13][14]:
- SISD,即单指令单数据。如图:4 次加法计算需要执行 4 次指令,从内存 load 和 store 4 次数据,即标量(Scalar, 一个标量就是一个单独的数)计算
- SIMD[15],单指令多数据。如图:4 次加法计算只需要执行 1 次指令,从内存 load 和 store 1 次数据,每次可以计算一组数据,即向量(vector, 一个向量就是一列数)计算

回到 StarRocks 的计算上来,对单核上的计算优化,如下就是要减少 CPU Time,减少 Cpu Time 的手段有 2:
- 减少指令数量,这就可以用到 SIMD,即所谓的向量化
- 减少 CPI,主要是减少分支预测失败和 Cache Miss,这里不展开
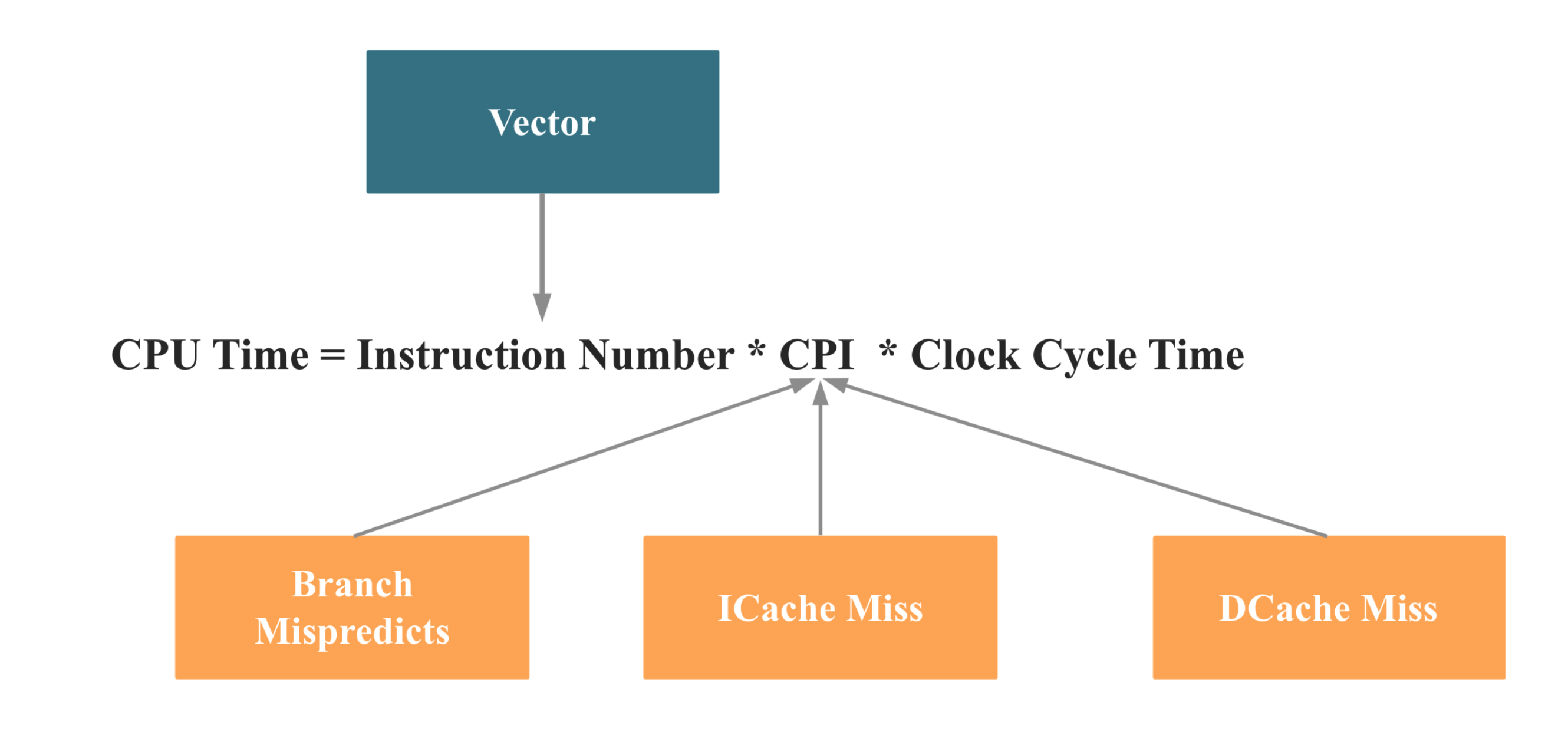
看个例子:如图,使用向量化计算后性能可以得到数倍的一个提升
当然,我们知识介绍了向量化计算的思想,如果要在数据库层面实现向量化,是个巨大的工程。需要存储结构层面、算子层面、内存中的数据组织层面都要做适配。比如列式存储、按列处理就更适合向量化计算。详情可见:
https://mp.weixin.qq.com/s/J6_L6ijaiuuO6FXCa-AW9w
展望未来
现在 OLAP 数据库会面临几个问题:
- 存储计算一体化,扩存储就得扩计算,浪费资源;
- OLAP 场景主要是报表等,有比较强的潮汐现象,白天资源满,满上资源比较空。然后得按照峰值来部署资源,造成资源浪费。
有鉴于此,所以:
- 存算分离:https://zhuanlan.zhihu.com/p/630277812
- 云原生化,serveless,让资源可以弹性伸缩,按需使用
还有一个趋势是 All in one
- HTAP
- HSAP
- presto on spark
引用
- cascadez cbo:https://zhuanlan.zhihu.com/p/365085770
- columbia cbo: https://zhuanlan.zhihu.com/p/464717139
- 开源优化器:https://www.infoq.cn/article/5o16ehoz5zk6fzpsjpt2
- 每天数百亿用户行为数据,美团点评怎么实现秒级转化分析?
- Comparing Three Real-Time OLAP Databases: Apache Pinot, Apache Druid, and ClickHouse
- https://zhuanlan.zhihu.com/p/355312398
- https://impala.apache.org/
- https://li.feishu.cn/docx/KGtndwglEom70NxsgFDcMo9AnMg
- https://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf
- https://mp.weixin.qq.com/s/AkTAibnAaM29aC5JJT58YQ
- https://mentalmodels4life.net/2016/08/14/apache-spark-vs-mpp-databases/
- https://mp.weixin.qq.com/s/fgNwk2DyijKM4D9L77LQNA
- https://zhuanlan.zhihu.com/p/31271788
- https://zhuanlan.zhihu.com/p/296677429
- https://en.wikipedia.org/wiki/Single_instruction,_multiple_data
- https://www.jianshu.com/p/a078fed07acc
- https://docs.starrocks.io/zh-cn/2.4/table_design/StarRocks_table_design
- https://mp.weixin.qq.com/s/aJ3FwDI6KprYYUwXzhl_-A
- https://blog.bcmeng.com/post/fastest_database.html
- https://en.wikipedia.org/wiki/Comparison_of_OLAP_servers
- https://xie.infoq.cn/article/4bdf3da72bc868ad78cf6bf4b
- https://blog.bcmeng.com/post/mpp-grouped-excution-stage.html

