
引言
StarRocks,它的计算部分借鉴了 impala[1],存储部分借鉴了 Google Mesa[2]。而 Compaction 机制正是来源于 Google Mesa。
Mesa 是一个分析型的数据仓库系统(highly scalable analytic data warehousing system),主要用于谷歌的广告业务(分析、报表)中。它非常强调“实时性”,它要支持:
- Near Real-Time Update Throughput :实时的大批量的数据更新
- 实时更新:must support continuous updates
- qps 达到几百万:millions of rows updated per second
- Query Performance:point query 的 p99 要达到几百毫秒,就是要满足这种低时延的场景
- Atomic Update
- …
所以它采用了类似 LSM-tree[3] 的这种数据结构,牺牲了一些查询性能,但是换取了写性能的提升。而这种结构就避免不了要进行数据的 “Compaction”。所以 StarRocks 会在后台通过 Compaction 机制不断将小文件合并成有序的大文件,同时也会处理数据的删除、更新等操作。
备注:下图是 Lsm-tree 的 compaction,思想类似,但是 StarRocks 和 Mesa 的机制有不同之处。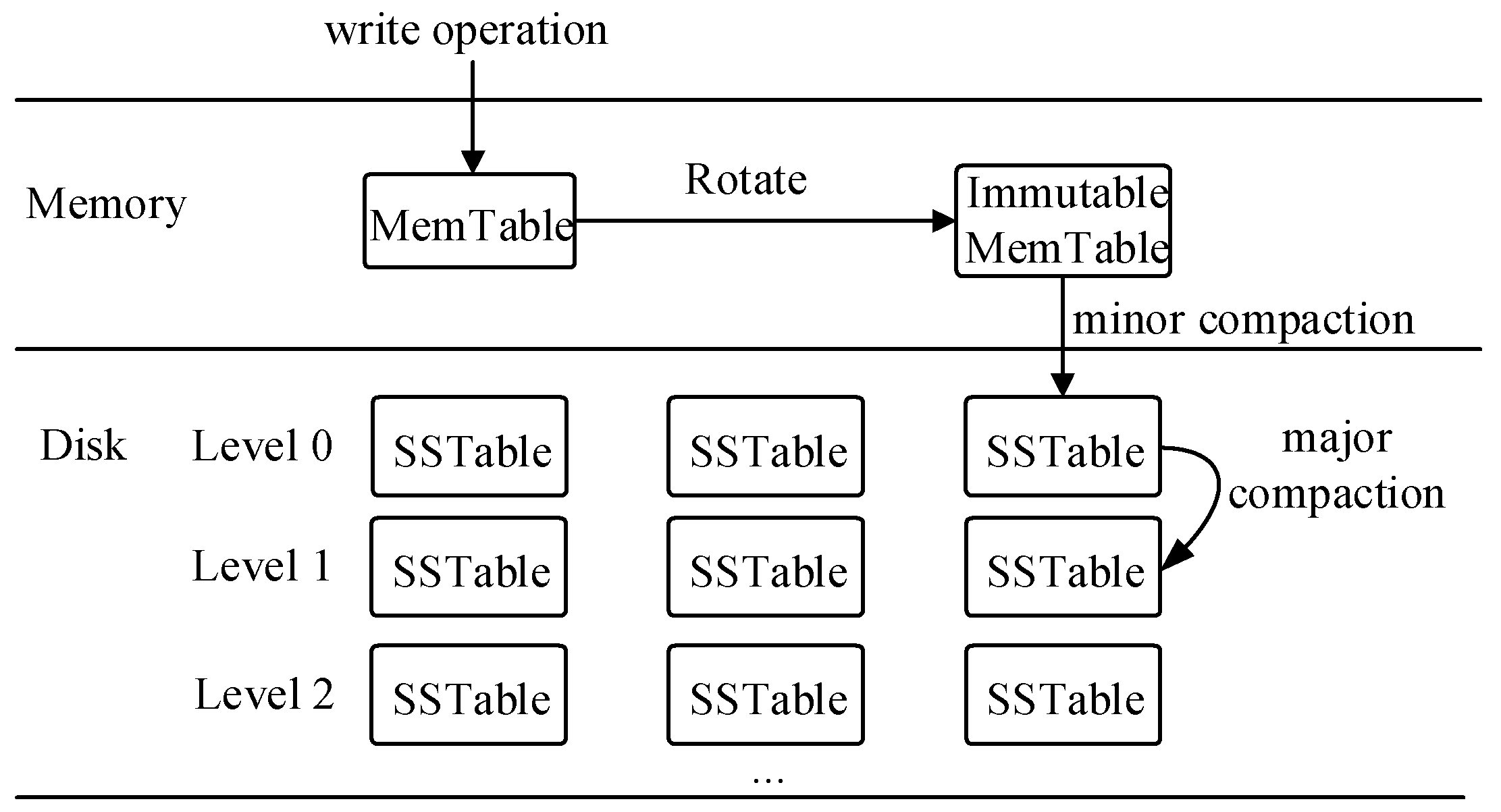
(LSM-tree compaction)
存储结构介绍
StarRocks 存储结构由 4 层结构组成。

Rowset
- Rowset 是 Tablet 中一次数据变更的数据集合[4],数据变更包括了数据导入、删除、更新等。所谓一次数据变更就是一次导入事务,比如一次 Stream Load 导入就对应一个新的 Rowset。
- Rowset 按版本信息进行记录。版本由 start_version、end_version 两个属性构成,维护数据变更的记录信息。通常用来表示 Rowset 的版本范围。
- 在一次新导入后生成一个 start_version,end_version 相等的 Rowset
- 在 Compaction 后生成一个带范围的 Rowset 版本

Segment
- 表示 Rowset 中的数据分段,多个 Segment 构成一个 Rowset。Segment 文件可以有多个,一般按照大小进行分割,默认为 256MB。
- Segment File(类似 SSTable) 是**真正的数据文件[5]**,是一个“类 parquet” 的列存储格式。整体的文件格式分为数据区域,索引区域和 footer 三个部分,如下图所示:

数据写入流程
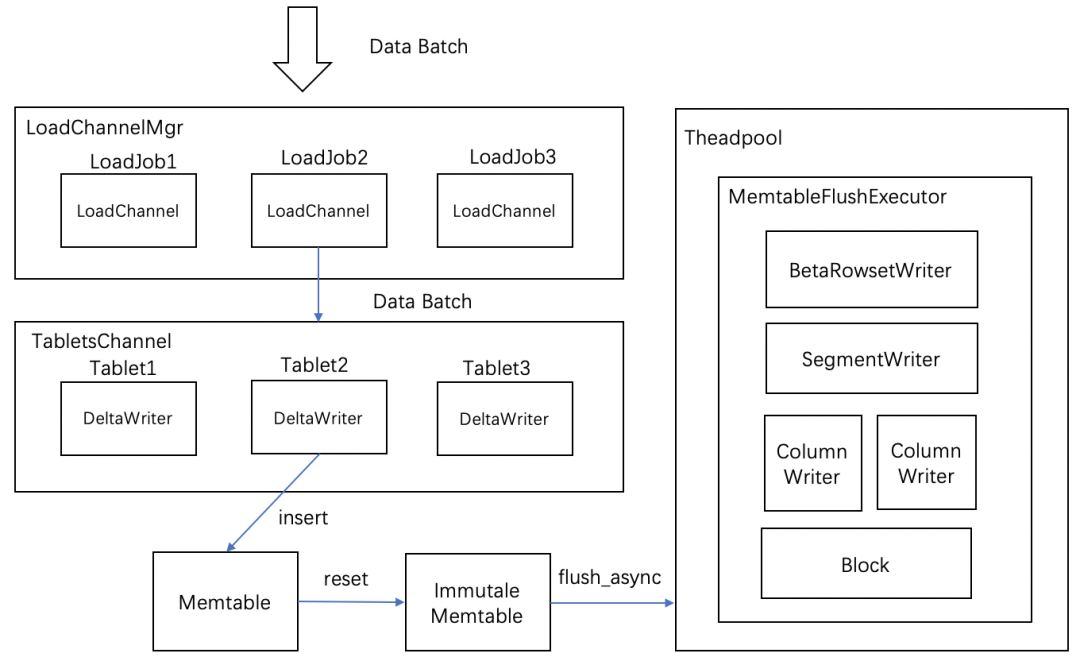
- 当一个 Memtable 写满时(默认为 100M),调用 RowsetWriter 将 Memtable 的数据会 flush 到磁盘上
- RowsetWriter 调用 SegmentWriter, 将数据和索引写入到磁盘
Compaction
To enforce update atomicity, Mesa uses a multi-versioned approach. Mesa applies updates in order by version number, ensuring atomicity by always incorporating an update entirely before moving on to the next update. Users can never see any effects from a partially incorporated update.[2]
如上 Mesa 中所述,为了实现开头说的数据更新的“原子性”(Atomic Update),数据采用了 MVCC (想想 rowset 中的版本,一次导入是一个事物,完成后形成一个版本),实现了 snapshot isolation。但是这也带来了一些问题:
- 过多的数据版本会带来更多的存储开销:一条数据如果多次更新,被存储在不同的 rowset 中,便会发生冗余的存储。
- 过多的数据版本会带来查询时效的降低:查询采用 Merge on read 的模式,在查询时要 merge 所有版本的数据来产生最终的聚合结果。如果采用预聚合的方式(copy on write),每次更新都进行预聚合,那么成本也非常高昂。
所以为了解决以上的问题来平衡读写,Mesa 采用了 2 级 Compaction 机制[2],这样可以:
- 合并多个数据版本,避免在读取时大量的 Merge 操作。这可以看作讲查询时进行所有 merge 的时间平摊到了一个更长的时间轴上,从而提高了查询时效。
- 避免大量的数据版本导致的随机 I

当然 StarRocks 借鉴了这种机制但并不完全一样:会根据一定的策略对这些 Rowset 进行合并,将小文件合并成大文件,进而提升查询性能。compaction 也是分两种:
- Cumulative Compaction: cumulative compaction 主要负责将多个最新导入的 rowset 合并成较大的 rowset
- Base Compaction:将 cumulative compaction 产生的 rowset 合入到 start version 为 0 的基线数据版本(Base Rowset)中,是一种开销较大的 compaction 操作
- 这两种 compaction 的边界通过 cumulative point 来确定。base compaction 会将 cumulative point 之前的所有 rowset 进行合并,cumulative compaction 会在 cumulative point 之后选择相邻的数个 rowset 进行合并[6]

合并流程
合并流程大体分为 4 步,其中 Base Compaction 和 Cumulative Compaction 主要是第二步计算 Cumulative_point[6] 不一样。
Compaction 任务的产生采用了生产者-消费者模式。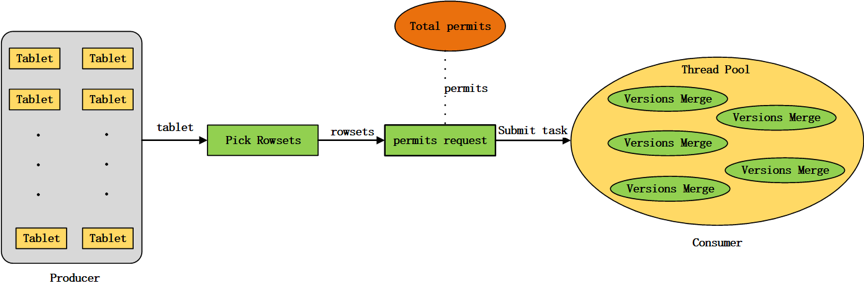
- Compaction 任务是一个** IO 密集型**任务,为了保证其不占用过多 io 资源[8],限制了每个磁盘上能够同时进行的 Compaction 任务数量,默认
- base_compaction_num_threads_per_disk = 1
- cumulative_compaction_num_threads_per_disk = 1
- Compaction 任务同时也是**内存密集型[8]**任务(本质是多个有序文件的多路归并排序过程),为了限制内存使用
- 内存使用量与本次 compaction 任务合并的文件数量有关,因此限制了每次任务包含的数据版本数,默认(singleton 其实是 mesa 中的概念[13],对应 rowset)
- max_base_compaction_num_singleton_deltas = 100。
- max_cumulative_compaction_num_singleton_deltas = 1000
- 为了调节 BE 节点 compaction 的内存使用量增加了对 compaction 任务提交的 permission 机制。
- 内存使用量与本次 compaction 任务合并的文件数量有关,因此限制了每次任务包含的数据版本数,默认(singleton 其实是 mesa 中的概念[13],对应 rowset)
- 在一轮任务生产过程中,会从每个磁盘各选择出一个 tablet 执行 compaction 任务,目前的策略是每生成 9 个 CC 任务,生成一个 BC 任务。如何选择 Tablet 参见 [6]
这种方式其实不适合数据高频更新、高频点查的场景,比如主键模型的场景。为什么呢,因为高频更新就会生成大量的 rowset,一方面会增加 compaction 的压力;另一方面查询时就要 merge 更多的版本,查询时效受影响。所以因此 StarRocks 针对这个场景(主键模型)做了优化,见[11]。
Cumulative Compaction
cumulative compaction 不会将 delete 操作删除的数据行进行真正地删除,这部分工作会在 base compaction 中进行。Doris 的 cumulative compaction 每次会在 cumulative point 之后选择相邻的数个 rowset 进行合并,主要包含 5 个步骤
Base Compaction
Doris 的 base compaction 会将 cumulative point 之前的所有 rowset 进行合并,base compaction 过程中会将 delete 操作删除的数据行真正地删除。
Compaction 问题排查
如图[12]:
这 3 种导入方式都会频繁生成大量的版本即 rowset 文件,增加 compaction 的压力
- insert into values 和 jdbc 频繁导入,每次导入都是一个事务,会形成一个 rowset。试想通过 insert into 每次导入 1 条数据,那么 100w 数据就会生成 100w 个 rowset,需要 compaction 去合并。
- 同理,高频 stream load 可能导致 compaction 的速度跟不上导入的速度,形成导入的压力,影响查询性能,因为查询时候就得做更多版本 merge。

Compaction 出现压力时,调优可参考:[7][8][9]
引用
- Impala
- Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing
- DB 存储引擎知识系列之三:LSM-Tree 存储引擎详细分解_mob604756f33d49 的技术博客_51CTO 博客
- 【Doris 全面解析】存储层设计介绍 2——写入流程、删除流程分析
- 【Doris 全面解析】存储层设计介绍 1——存储结构设计解析
- 技术解析 | Doris Compaction 机制解析百度百度开发者中心_InfoQ 写作社区
- Doris 最佳实践-Compaction 调优(1) - 墨天轮
- Doris 最佳实践-Compaction 调优(2) - 墨天轮
- Doris 最佳实践-Compaction 调优(3) - 墨天轮
- 编程小梦|Google Mesa 论文解读
- StarRocks 技术内幕:实时更新与极速查询如何兼得
- 2/22 19:00 直播 | StarRocks 实战系列 Ep.2—导入优化&问题排查(转发、打卡还可以获得积分奖品!)
- https://blog.csdn.net/qq_35200943/article/details/127498751
- https://www.slidestalk.com/doris.apache/61900?video

