
Summary
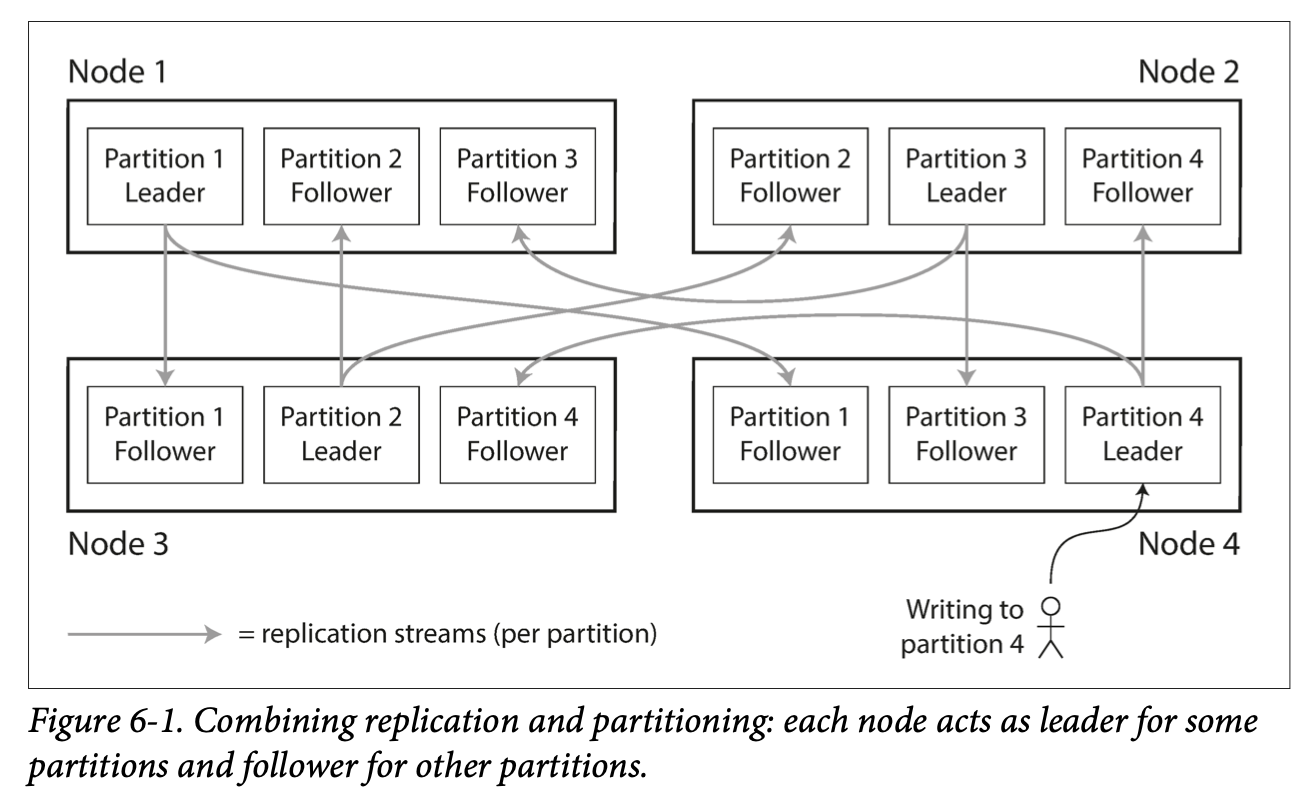
Partition 可以结合 Replication, 每个 partition 可以有多个 Replication 以保持高可用,如图:
Partition(sharding): partitioning a large dataset into smaller subsets, that each piece of data (each record, row, or document) belongs to
exactly onepartition.使用 partition 可以分散读写,可以横向扩展。
The main reason for wanting to partition data is scalability: 数据和写入都可以分散到多个机器上去,以避免 hot spots。数据的 split 要合理,避免数据倾斜,同时要考虑 node 上下线的问题。
2 种 partitioning 的方式:
Key range partitioning:key are sorted,partition 中也按 key 有序存储
- 优点: 高效的 range query
- 缺点: 访问的 key 相对集中时候的热点问题
- rebalance 策略: dynamically by splitting the range into two subranges when a partition gets too big.
Hash partitioning: 将 key hash 到对应的 partition,key 是无的序,从而换取更均匀的数据分布
- 优点: 更均匀的数据分布
- 缺点: 低效的 range query
- rebalance 策略: common to create a fixed number of partitions in advance, to assign several partitions to each node, and to move entire partitions from one node to another when nodes are added or removed
可以混合 2 种 partition 方式: using one part of the key to identify the partition and another part for the sort order.
Secondary index 的 2 种 partition 方式:
- Document-partitioned indexes (
local indexes): 和主键存储在同一个 partition,所以更新时只需更新单个 partition, 但是读取时需要聚集多个 partition 的数据 - Term-partitioned indexes (
global indexes): 分散在各个分区中,更新的时候需要更新多个,但是读取的时候只需要读取一个 partition
Partitionoing of Key-Value Data
Our goal with partitioning is to spread the data and the query load evenly across nodes.
如果 partition 不能平均分配, 就会出现数据倾斜和 hot spot 问题。
Partitioning by Key Range
One way of partitioning is to assign a continuous range of keys (from some minimum to some maximum) to each partition
In order to distribute the data evenly, the partition boundaries need to adapt to the data.
Within each partition, we can keep keys in sorted order (SSTables and LSM-Trees)
劣势: 如果频繁访问部分 key,会造成 hot spots 问题。
Partitioning by Hash of Key
使用 hash function 对 key 求 hash 值,you can assign each partition a range of hashes (rather than a range of keys), and every key whose hash falls within a partition’s range will be stored in that partition。如图:

优势: This technique is good at distributing keys fairly among the partitions. The partition boundaries can be evenly spaced.
劣势: range query 需要读取多个 partitoin,相比于 key range parition,比较低效。
Partitioning and Secondary Indexes
A secondary index usually doesn’t identify a record uniquely but rather is a way of searching for occurrences of a particular value.
二级索引在关系型数据库中比较普遍。由于实现的复杂性,许多 k,v 存储(如 hbase)避免使用二级索引。搜索引擎(如 es)使用二级索引。
The problem with secondary indexes is that they don’t map neatly to partitions.
There are two main approaches to partitioning a database with secondary indexes: document-based partitioning and term-based partitioning.
Partitioning Secondary Indexes by Document(local index)
In this indexing approach, each partition is completely separate: each partition maintains its own secondary indexes, covering only the documents in that partition.如图:

优势: 实现简单,写入和更新 index 比较简单高效。
劣势: 读取成本高,需要读取所有 partition, Even if you query the partitions in parallel.
Partitioning Secondary Indexes by Term(global index)
Term: 来自全文索引的概念,这里指的是: where the terms are all the words that occur in a document.
global index that covers data in all partitions,如果所有 index 都存储在一台 node 会成为瓶颈,所以 index 也需要 partitioned,可以通过 term 自身(方便 range scan)或者 hash 的方式(可以均匀分散)对 term index 进行 partition。 如图:
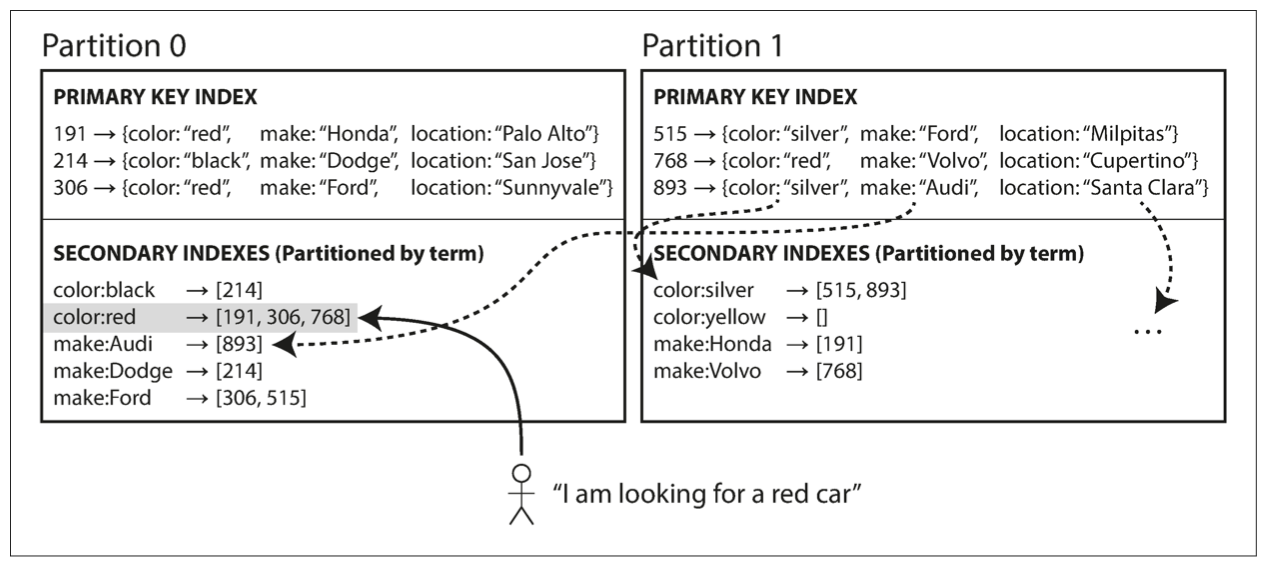
好处: 使用索引可以只读取相应的 partition, 提交读取效率。
坏处: 因为写入的时候需要更新多个 partition 中的 index,所以写效率降低且复杂。
In practice, updates to global secondary indexes are often asynchronous, 因此 index 写入后不是立即可见的, 所以需要 distributed transactioon 来保证所有写入 partition 的索引的正确和立即可见。
Rebalancing Partitions
The process of moving load from one node in the cluster to another is called rebalancing.
Rebalancing 需满足:
- 将 load(存储,读写 load)公平的分配到集群的机器上。
- Rebalancing 的同时, db 可以继续提供读写服务
- 要降低网络和磁盘 io,在 node 间只移动必要的数据。
Strategies for Rebalancing
We need an approach that doesn’t move data around more than necessary.
hash mod N
The problem with the mod N approach is that if the number of nodes N changes, most of the keys will need to be moved from one node to another
Fixed number of partitions
使用固定数量的 partitions is operationally simpler,然而选取合适的 partition 数量是非常困难的。而且在增减机器时候也有不必要的数据移动,如图:
如图:

Dynamic partitioning
当 partiton 中数据量增长到一个阈值的时候,可以 split 为 2 个partiton;同时,如果有数据删除,partiiton 变小,可以合并相邻 partition。
优势: the number of partitions adapts to the total data volume
缺陷: 当数据量小的时候被分配到一个 partition 中,开始所有的读写都会打到这个 partition, 为了缓解这个问题,可以预先分配一些 partition,但这需要 know what the key distribution is going to look like。
Partitioning proportionally to nodes
在以上的 cases 中, the number of partitions is independent of the number of nodes.
To have a fixed number of partitions per node, this approach also keeps the size of each partition fairly stable.这个方式可以很好的适应数据规模的变化,但是在增减机器 rebanlancing 的时候需要注意避免形成 unfailrly partition.
Operations: Automatic or Manual Rebalancing
自动 rebalancing 十分方便,但是是不可预测的,同时 automation can be dangerous in combination with automatic failure detection, 可能导致级联的错误。因此让人介入 rebalance 是比较好的。
Request Routing
service discovery 问题, client 如何知道要访问哪台机器? 有 3 种方式,如图:

Many distributed data systems rely on a separate coordination service such as ZooKeeper to keep track of this cluster metadata,如图:

Parallel Query Execution
The MPP(massively parallel processing) query optimizer breaks this complex query into a number of execution stages and partitions, many of which can be executed in parallel on different nodes of the database cluster。如各种分布式计算引擎: mr, spark, presto.

