
?
- what
degreethey are avoidable - how to think about the
stateof a distributed system - how to
reason aboutthings that have happened
Summary
不同于单机,分布式系统中问题是无法避免的,本节主要探讨分布式系统中会遇到的以下问题:
- network 问题,比如网络不通导致节点之间的通信问题
- clock 问题,如:不同 node 的 clock 不同步
- process 问题,如: process may pause for a substantial amount of time at any point in its execution
Partial failure: In a distributed system, there may well be some parts of the system that are broken in some unpredictable way, even though other parts of the system are working fine.
partial failure 是不可预测的,This
nondeterminismand possibility of partial failures is what makes distributed systems hard to work with。
单机和 supercomputer 面对 partial failure 时简单让整个系统崩溃重启就行,这是由于应用场景和硬件设计决定的。对于分布式系统,通常由许多跨地域的普通机器通过以太网进行组织,并为用户提供线上服务,因此出现错误时候简单的重启系统是不可接受的。所以 If we want to make distributed systems work, we must accept the possibility of partial failure and build fault-tolerance mechanisms into the software.
分布式系统中 partial failure 无法避免,因此需要 fault-tolerance 机制
Unreliable Networks
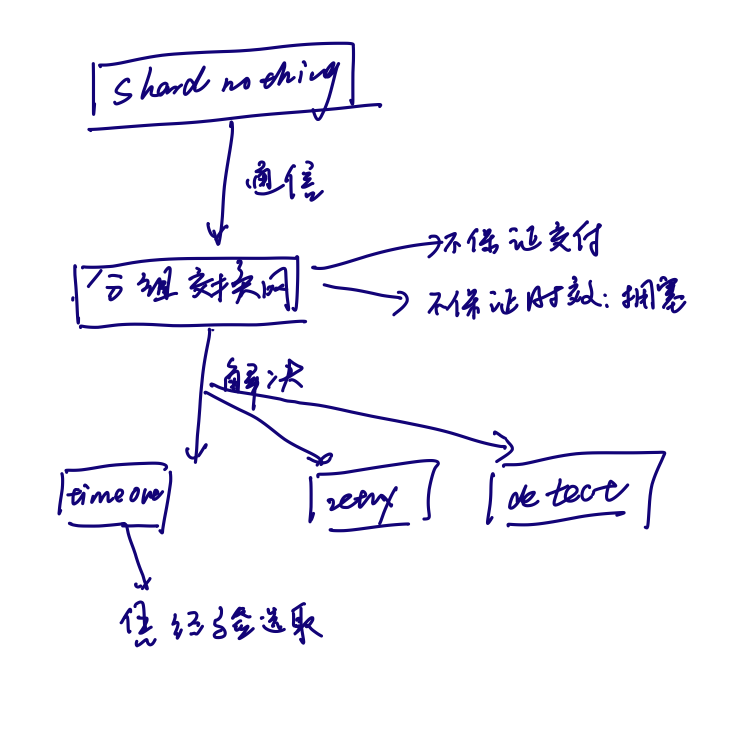
分布式系统通常采用 shared-nothing 架构, node 之间只能通过网络通信。通常使用的网络是 asynchronous packet networks(如因特网,以太网).
Async network 无法保证数据交付和交付时效,所以会导致以下问题:
- request lost
- request 延迟
- The remote node may have failed or 无法服务。
- response lose
- response 延迟
The usual way of handling this issue is a timeout.
在实际使用中,由于系统和人为因素,网络问题总是无法避免。However, you do need to know how your software reacts to network problems and ensure that the system can recover from them. It may make sense to deliberately trigger network problems and test the system’s response.
Detecting Faults
Many systems need to automatically detect faulty nodes。
In some specific circumstances you might get some feedback to explicitly tell you that something is not working
If you want to be sure that a request was successful, you need a positive response from the application itself
but in general you have to assume that you will get no response at all. You can retry a few times
Timeouts and Unbounded Delays
如果以 timout 作为 fail 机制,Timeout 如何选取,过长过短都会有问题。
如果系统保证 request 和 reponse 的最大时间,那么可以根据这些设置 timeout, 可惜多数系统并不做这种保证。
Prematurely declaring a node dead is problematic:
2d + r would be a reasonable timeout to use.
很多系统对 request 交付和 response 的最大时间是不做保证的。
For failure detection, it’s not sufficient for the system to be fast most of the time: if your timeout is low, it only takes a transient spike in round-trip times to throw the system off-balance.
Network congestion(拥塞) and queueing
Similarly, the variability of packet delays on computer networks is most often due to queueing:
- 比如大量请求一个 node 导致网络拥塞,交换器在队列满后会丢弃后续的数据,这需要 resent request.
- request packet 到 os 时,如果所有 cpu busy, packet 需要排队。
- In virtualized environments
- TCP performs flow control: This means additional queueing at the sender before the data even enters the network.
In public clouds and multi-tenant datacenters,因为 resource 都是共享的,所以资源缺乏管理的时候,就容易发生拥塞
In such environments, you can only choose timeouts experimentally:
Even better, rather than using configured constant timeouts, systems can continually measure response times and their variability (jitter), and automatically adjust timeouts according to the observed response time distribution.
Synchronous(电路交换) Versus Asynchronous(分组交换) Networks
电路交换: 如传统电话线路,通信时端到端建立连接,并且独占带宽资源。
好处:可以建立可靠的,保证最大递交延迟的通信链路
坏处:由于带宽独占,资源被静态切分导致资源利用率不高
分组交换:如 Ethernet 和 IP 网,带宽资源动态分配
好处:更高的资源利用率
坏处:会带来拥塞问题
而分布式应用通过 ip 网络通信,所以 queuing 问题无法避免。所以:Consequently, there’s no “correct” value for timeouts they need to be determined experimentally.
Ethernet and IP are packet-switched protocols, which suffer from queueing and thus unbounded delays in the network. 所以无法构筑 establish a guaranteed maximum round-trip time 网络.
Why do datacenter networks and the internet use packet switching? The answer is that they are optimized for bursty traffic. 使用因特网,doesn’t have any particular bandwidth requirement we just want it to complete as quickly as possible.
TCP dynamically adapts the rate of data transfer to the available network capacity.
With careful use of quality of service (QoS, prioritization and scheduling of packets) and admission control (rate-limiting senders), it is possible to emulate circuit switching on packet networks, or provide statistically bounded delay.
Unreliable Clocks
还是网络问题导致的通信时延让 clock 问题变得棘手。由于每个 node 上 clock 的误差,所以 Time-of-Day Clock 和 monotonic clock 都无法用来标识 event 发生顺序,需要使用 logical clock.
It is possible to synchronize clocks to some degree: the most commonly used mechanism is the Network Time Protocol (NTP), which allows the computer clock to be adjusted according to the time reported by a group of servers.
Monotonic Versus Time-of-Day Clocks
Time-of-day clocks
it returns the current date and time according to some calendar
time-of-day 使用 ntp 进行时间同步,当其和 ntp server 不一致时,会强制重置本地 local clock, These jumps, as well as the fact that they often ignore leap seconds, make time-of-day clocks unsuitable for measuring elapsed time.
Monotonic clocks
A monotonic clock is suitable for measuring a duration (time interval), The name comes from the fact that they are guaranteed to always move forward (whereas a time-of-day clock may jump back in time).
the absolute value of the clock is meaningless. 因为 monotonic clocks 不存在在不同节点之间同步的问题,所以在分布式系统使用其来衡量 elaspsed time 是很好的.
Clock Synchronization And Accuracy
hardware clocks and NTP can be fickle beasts
If your NTP daemon is misconfigured, or a firewall is blocking NTP traffic, the clock error due to drift can quickly become large.
Relying on Synchronized Clocks
Robust software needs to be prepared to deal with incorrect clocks.
Part of the problem is that incorrect clocks easily go unnoticed
Thus, if you use software that requires synchronized clocks, it is essential that you also carefully monitor the clock offsets between all the machines.
Timestamps for ordering events
由于网络问题等,各个 node 上的 physical lock 之间存在差值,所以 分布式环境下使用 physical lock(time-of-day and monotonic clocks) 来标识 event 的发生顺序是无法保证正确性的。所以需要引入 logical clocks which are based on incrementing counters,are a safer alternative for ordering events
Clock readings have a confidence interval
通过 time-of-day clock 获取的时间往往在一个误差范围内 Thus, it doesn’t make sense to think of a clock reading as a point in time—it is more like a range of times。The uncertainty bound can be calculated based on your time source.
Synchronized clocks for global snapshots
The most common implementation of snapshot isolation requires a monotonically increasing transaction ID.
在分布式环境下实现 snapshot isolation 时,由于 clock 之间的不一致,实现一个 monotonically increasing transaction ID 比较困难,甚至 With lots of small, rapid transactions, creating transaction IDs in a distributed system becomes an untenable bottleneck.
在 google spanner 中,使用 confidence time interval 来实现 monotonically increasing transaction ID. In order to keep the wait time as short as possible, Spanner needs to keep the clock uncertainty as small as possible; for this purpose, Google deploys a GPS receiver or atomic clock in each datacenter, allowing clocks to be synchronized to within about 7 ms
google spanner 怎么实现的?
Process Pauses
在分布式环境中, thread 可能会 pause so long, 比如 gc。由于在分布式系统中 has no shared memory, only messages sent over an unreliable network,所以单机中使用的并发机制如信号量,锁也都无法使用。
因此 A node in a distributed system must assume that its execution can be paused for a significant length of time at any point, even in the middle of a function
Response time gurantees(怎么解决?)
在一些要求实时的系统中, there is a specified deadline by which the software must respond; if it doesn’t meet the deadline, that may cause a failure of the entire system. These are so-called hard real-time systems.
实现实时系统: Providing real-time guarantees in a system requires support from all levels of the software stack。For these reasons, developing real-time systems is
very expensive, and they are most commonly used in safety-critical embedded devices. Moreover, “real-time” is not the same as “high-performance”—in fact, real-time systems may have lower throughput, since they have to prioritize timely responses above all else所以: For most server-side data processing systems, real-time guarantees are simply not economical or appropriate. Consequently, these systems must suffer the pauses and clock instability that come from operating in a non-real-time environment.
Limiting the impact of gc
An emerging idea is to treat GC pauses like brief planned outages of a node, and to let other nodes handle requests from clients while one node is collecting its garbage. This trick hides GC pauses from clients and reduces the high percentiles of response time. Some latency-sensitive financial trading systems use this approach.
A variant of this idea is to use the garbage collector only for short-lived objects (which are fast to collect) and to restart processes periodically, before they accumulate enough long-lived objects to require a full GC of long-lived objects
These measures cannot fully prevent garbage collection pauses, but they can usefully reduce their impact on the application.
Knowledge, Truth, and Lies
which distributed systems are different from programs running on a single computer: there is no shared memory, only message passing via an unreliable network with variable delays, and the systems may suffer from partial failures, unreliable clocks, and processing pauses.
A node in the network cannot know anything for sure—it can only make guesses based on the messages it receives (or doesn’t receive) via the network. A node can only find out what state another node is in (what data it has stored, whether it is correctly functioning, etc.) by exchanging messages with it.
In a distributed system, we can state the assumptions we are making about the behavior (the system model) and design the actual system in such a way that it meets those assumptions。
由于分布式系统中,节点只能依赖网络传递消息来进行状态判断,导致网络本身的问题和系统的问题无法区分。鉴于底层(os,network)等的不可靠,只能假设这些不可靠因素存在,在上层构筑可靠的系统。
The Truth Is Defined by the Majority
分布式中,单个节点不可信,所以要依赖多个节点进行仲裁
A distributed system cannot exclusively rely on a single node, because a node may fail at any time, potentially leaving the system stuck and unable to recover. Instead, many distributed algorithms rely on a quorum, that is, voting among the nodes.
仲裁策略:
The individual node must abide by the quorum decision and step down.A majority quorum allows the system to continue working if individual nodes have failed
The leader and the clock
Frequently, a system requires there to be only one of some thing.使用仲裁,这些 only one 也不一定可以被保证。如 the chosen one 问题:
If a node continues acting as the chosen one, even though the majority of nodes have declared it dead, it could cause problems in a system that is not carefully designed.
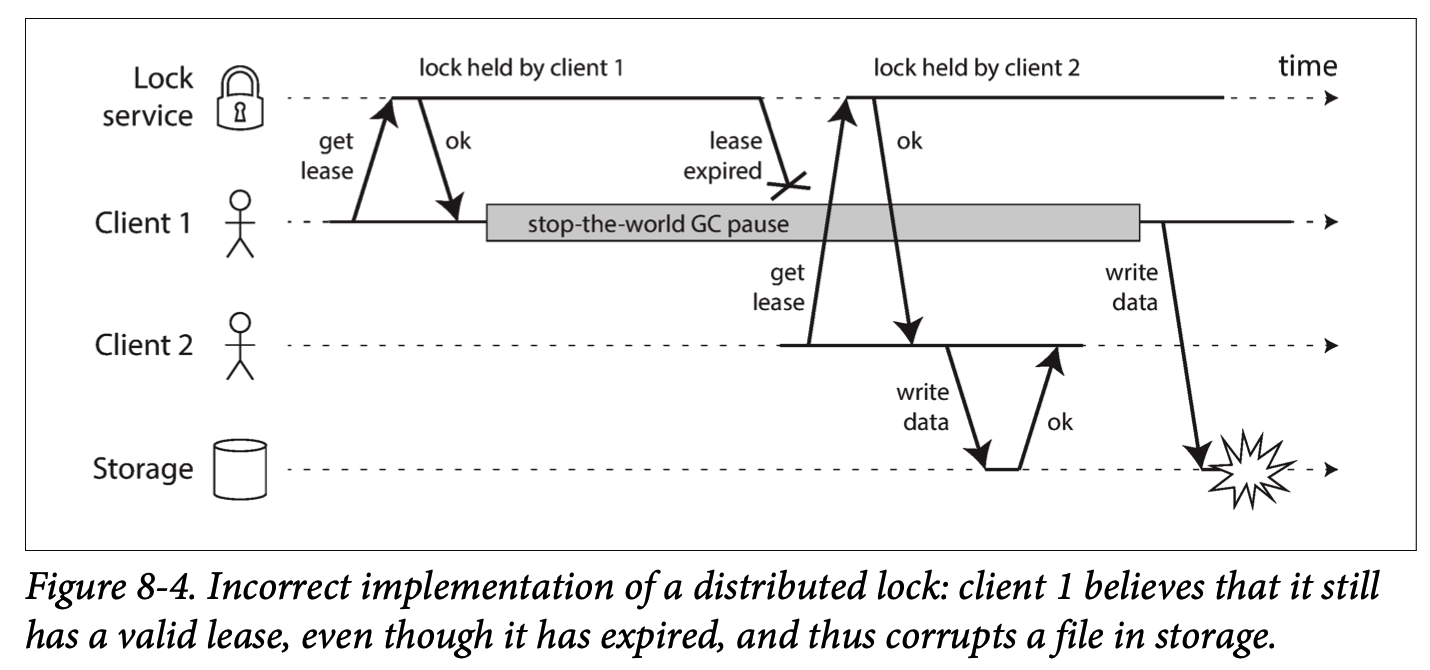
Fencing tokens
使用 fencing 技术来解决 the chosen one 问题.
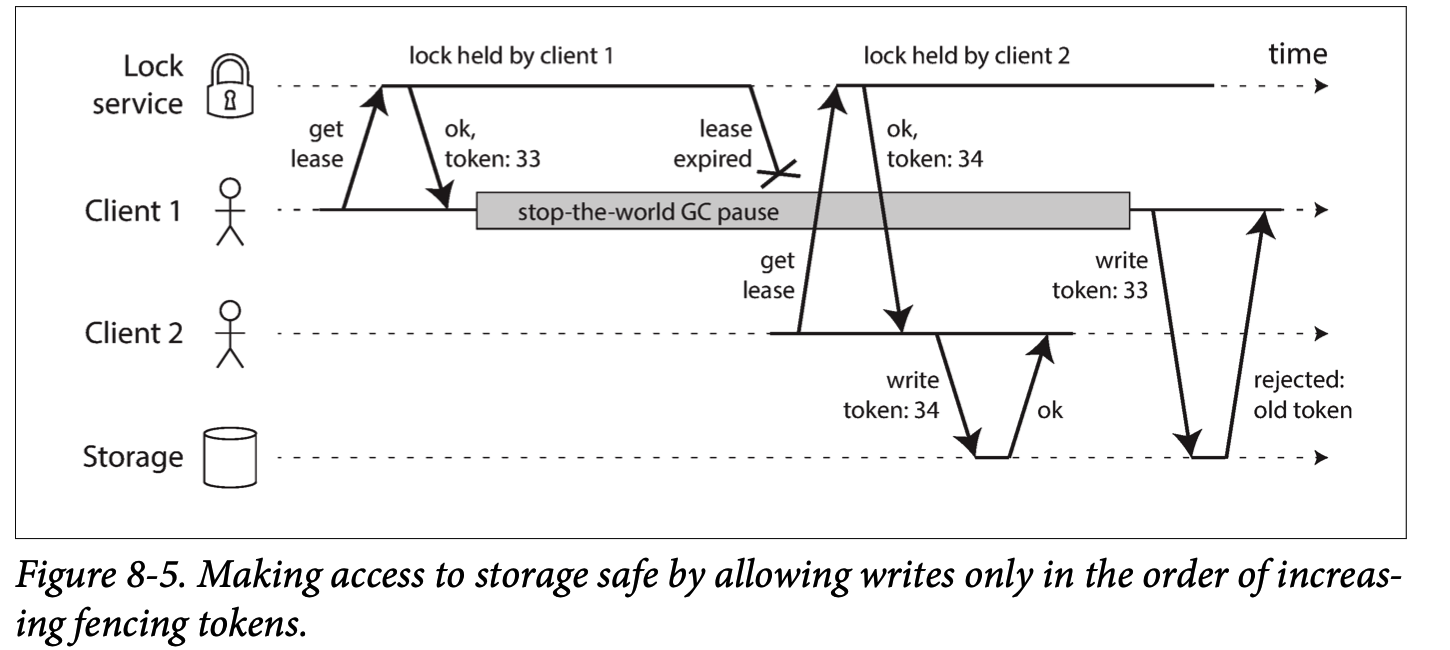
Note that this mechanism requires the resource itself to take an active role in checking tokens by rejecting any writes with an older token than one that has already been processed—it is not sufficient to rely on clients checking their lock status themselves.
In server side, it is a good idea for any service to protect itself from accidentally abusive clients.
Byzantiine Faults
拜占庭将军问题实际上指的是在一个有 n 个节点的集群内,有 t 个节点可能发生任意错误的情况下,如果 n <= 3t,一个正确的 consensus 不可能达成
假设节点总数是N,叛徒将军数为F,则当 N >= 3F+1 时,问题才有解,共识才能达成,这就是Byzantine Fault Tolerant(BFT)算法。
在仲裁的时候,如果 node lie 那么就会有拜占庭将军问题,在分布式系统中,所有 node 都是自己设置的,可以不必考虑拜占庭问题,在区块链等对等网络中需要考虑。
Although we assume that nodes are generally honest, it can be worth adding mechanisms to software that guard against weak forms of “lying”, for example, invalid messages due to hardware issues, software bugs, and misconfiguration.
System Model and Reality
system model, which is an abstraction that describes what things an algorithm may assume.
To timing assumptions model:
- Synchronous model: it just means you know that network delay, pauses, and clock drift will never exceed some fixed upper bound. 由于现实中 unbounded delays 无法避免,所以这个 model 不切实际。
- Partially synchronous model: Partial synchrony means that a system behaves like a synchronous system most of the time, but it sometimes exceeds the bounds for network delay, process pauses, and clock drift。符合实际情况
- Asynchronous model: In this model, an algorithm is not allowed to make any timing assumptions—in fact, it does not even have a clock (so it cannot use timeouts).
Node Failure model:
- Crash-stop faults: 只有 crash(he node may suddenly stop responding at any moment) 导致 node fail, crash 后无法恢复
- Crash-recorvery faults: node crash 后可以通过 stable storage 存储的数据恢复,而内存中的数据会丢失
- Byzantine (arbitrary) faults
crash-recovery faults is generally the most useful model.
Correctness of an algorithms
To define what it means for an algorithm to be correct, we can describe its properties.
An algorithm is correct in some system model if it always satisfies its properties in all situations that we assume may occur in that system mode
但是最坏的情况下,如 all nodes crash 或者 all network delay infinitely long,算法将失效
Safety and liveness
To clarify the situation, it is worth distinguishing between two different kinds of properties: safety and liveness properties
An advantage of distinguishing between safety and liveness properties is that it helps us deal with difficult system models, with liveness properties we are allowed to make caveats
Safety: something bad will never happen
Liveness: something good will must happen (but we don’t know when)
https://zhuanlan.zhihu.com/p/37864854
Mapping system models to the real world
The system model is a simplified abstraction of reality,理想很丰满,现实很骨感,算法模型做了一些假设,但是现实中这些假设会被打破,还是需要做容错处理
Model 的作用(推断证明): They are incredibly helpful for distilling down the complexity of real systems to a manageable set of faults that we can reason about, so that we can understand the problem and try to solve it systematically.
Theoretical analysis and empirical testing are equally important.

