
?
- It turns out that there are deep connections between ordering, linearizability, and consensus. 阐明它们之间的关系?
- 相比于单机事务,分布式事务有何不同?如何实现?
- 了解 google spanner(事务) 和 zk(consensus) 的实现
- CAP 定理的理解
Summary
http://www.bailis.org/blog/linearizability-versus-serializability
Consistent
Linearizability: 提供 stronger consistency, make replicated data appear as though there were only a single copy, and to make all operations act on it atomically
- 优点: 易于理解
- 缺点: 对网络问题敏感,性能慢
Causality: which puts all operations in a single, totally ordered timeline, causality provides us with a weaker consistency model
- 优点: 对网络问题不敏感
- 使用场景受限
Consensus
Consensus algorithms are a huge breakthrough for distributed systems: they bring concrete
safety properties(agreement, integrity, and validity) to systems where everything else is uncertain, and they nevertheless remainfault-tolerant(able to make progress as long as a majority of nodes are working and reachable). They providetotal order broadcast, and therefore they can also implement linearizable atomic operations in a fault-tolerant way.
定义: Deciding something in such a way that all nodes agree on what was decided, and such that the decision is irrevocable.
使用场景:
- Linearizable compare-and-set registers
- Atomic transaction commit
- Total order broadcast
- Locks and leases
- Membership/coordination service
- Uniqueness constraint
Zookeeper:
- providing an “outsourced” consensus
- failure detection
membership service
Consistency Guaranteess
分布式 db 中,由于网络等因素,数据不一致一定会发生,因此 Most replicated databases provide at least eventual consistency。
eventual consistency: 所有 replicas 的数据最终会达到一致。
- this is a very weak guarantee—it doesn’t say anything about
whenthe replicas will converge - 难以使用和测试: you need to be constantly aware of its limitations and not accidentally assume too much
stronger consistency: 所有 replicas 数据总是保持一致
- 缺点: worse performance, less fault-tolerant
- 优势: easier to use correctly
distributed consistency is mostly about
coordinatingthe state of replicas in the face of delays and faults.
Linearizability:
3 个特质:
- Recency gurantee
- single operations on singel object
- time dependency and always move forward in time
定义:
Linearizability(atomic consistency) is a guarantee about single operations on single objects. It provides a real-time (i.e., wall-clock) guarantee on the behavior of a set of single operations (often reads and writes) on a single object。
Linearizability is a recency guarantee(once a new value has been written or read, all subsequent reads see the value that was written, until it is overwritten again) on reads and writes of a register (an individual object). It doesn’t group operations together into transactions.
Vs Serializability:
linearizability can be viewed as a special case of strict serializability where transactions are restricted to consist of a single operation applied to a single object.
[http://www.bailis.org/blog/linearizability-versus-serializability/]
使用场景:
- Locking and leader election: They use consensus algorithms to implement linearizable operations in a fault-tolerant way
- Constraints and uniqueness guarantees
- Cross-channel timing dependencies
Implementing Linearizable System
The most common approach to making a system fault-tolerant is to use replication? 怎么说
Single-leader replication(potentially linearizable): If you make reads from the leader, or from synchronously updated followers, they have the potential to be linearizable.
Consensus algorithms(linearizable): consensus protocols contain measures to prevent split brain and stale replicas.
Multi-leader replication(not linearizable): because they concurrently process writes on multiple nodes and asynchronously replicate them to other nodes.
Leaderless replication(probably not linearizable): sometimes claim that you can obtain “strong consistency” by requiring quorum reads and writes (w + r > n)
简单的使用 quorums,即使满足 w + r > n, 也不一定是 linearizable, 如:

The Cost of Linearizability
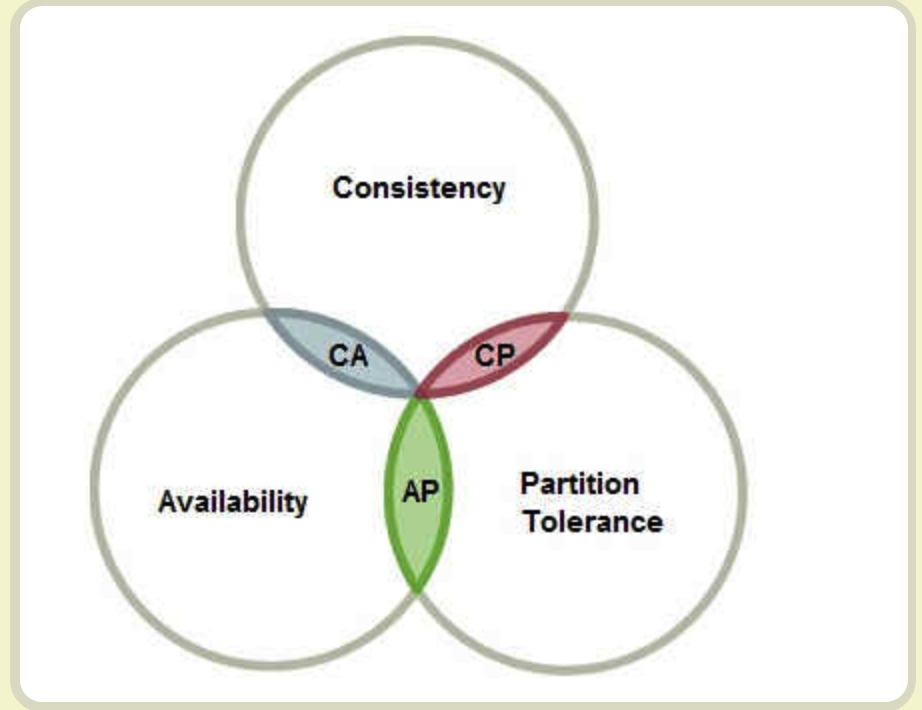
The CAP theorem:
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
CAP 的定义比较局限,The CAP theorem as formally defined is of very narrow scope: it only considers one consistency model (namely linearizability) and one kind of fault (network partitions,vi or nodes that are alive but disconnected from each other). It doesn’t say anything about network delays, dead nodes, or other trade-offs.
Linearizability and network delays:
A faster algorithm for linearizability does not exist, but weaker consistency models can be much faster, so this trade-off is important for latency-sensitive systems.
Ordering Guarantees
It turns out that there are deep connections between ordering, linearizability, and consensus.
Ordering and Causality
Ordering helps preserve causality:
- causal dependency: 比如事件的依赖顺序
- happened before relationship
- Cross-channel timing dependencies
- …
Causality imposes an ordering on events,These chains of causally dependent operations define the causal order in the system—i.e., what happened before what.
The causal order is not a total order
Causality: 在 Casual 中没有依赖的操作可以并发执行,因此这些操作无法比较,所以 Casual 是 partial order(偏序关系).
Linearizability: In a linearizable system, we have a total order of operations. Therefore, according to this definition, there are no concurrent operations in a linearizable datastore.
Linearizability is stronger than causal consistency
Linearizability implies causality is what makes linearizable systems simple to understand and appealing.
Causal consistency is the strongest possible consistency model that does not slow down due to network delays, and remains available in the face of network failures.
Capturing causal dependencies
In order to maintain causality, you need to know which operation happened before which other operation.
In order to determine causal dependencies, we need some way of describing the “knowledge” of a node in the system.
Causal consistency goes further: it needs to track causal dependencies across the entire database, not just for a single key
In order to determine the causal ordering, the database needs to know which version of the data was read by the application
Sequence Number Ordering
使用 logical clock 给 event 编号,we can use sequence numbers or timestamps to order events, and they provide a total order.
We can create equence numbers in a total order that is consistent with causality,先发生的 event 的 number 更小.
Lamport timestamps: 保证 causality
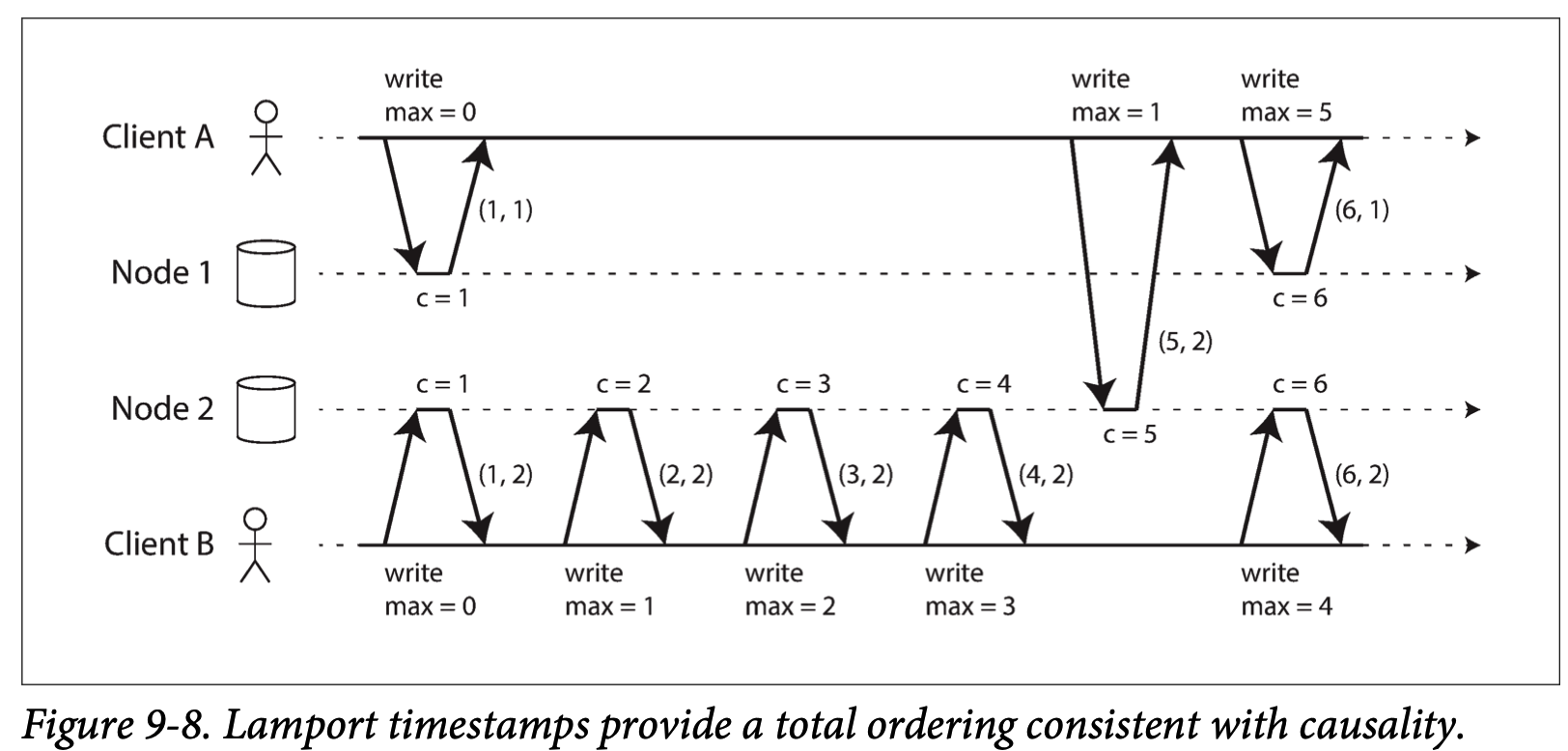
Each node has a unique identifier,and each node keeps a counter of the number of operations it has processed. The Lamport timestamp is then simply a pair of (counter, node ID). It provides total ordering.
原理解释:
- [https://jameshfisher.com/2017/02/12/what-are-lamport-timestamps/]
- [https://www.cnblogs.com/bangerlee/p/5448766.html]
Total Order Broadcast
This idea of knowing when your total order is
finalizedis captured in the topic of total order broadcast.
Total order broadcast is usually described as a protocol for exchanging messages between nodes, Two safety properties always be satisfied:
- Reliable delivery: msg 需要被 delivered 到所有 node
- Messages are delivered to every node in the same order.
This is no coincidence: it can be proved that a linearizable compare-and-set (or increment-and-get) register and total order broadcast are both equivalent to consensus. That is, if you can solve one of these problems, you can transform it into a solution for the others. This is quite a profound and surprising insight!
Distributed Transactions and Consensus
Atomic commit,即保证分布式事务的原子性,需要依赖 consensus algo,2PC is a kind of consensus algorithm, which solving atomic commit.
Atomic Commit and Two-Phase Commit(2PC)
Atomicity prevents failed transactions from littering the database with half-finished results and half-updated state.
From single-node to distributed atomic commit
存储硬件层面保证: Thus, it is a single device (the controller of one particular disk drive, attached to one particular node) that makes the commit atomic.
节点层面保证: A node must only commit once it is certain that all other nodes in the transaction are also going to commit, A transaction commit must be irrevocable。
应用层面保证: However, from the database’s point of view this is a separate transaction, and thus any cross-transaction correctness requirements are the application’s problem
Introduction to two-phase cmmit
Two-phase commit is an algorithm for achieving atomic transaction commit across multiple nodes—i.e., to ensure that either all nodes commit or all nodes abort.
在分布式系统里,每个节点都可以知晓自己操作的成功或者失败,却无法知道其他节点操作的成功或失败。当一个事务跨多个节点时,为了保持事务的原子性与一致性,需要引入一个协调(Coordinator)来统一掌控所有参与者(Participant)的操作结果,并指示它们是否要把操作结果进行真正的提交或者回滚.
2PC顾名思义分为两个阶段,其实施思路可概括为:
- 投票阶段(voting phase): 参与者将操作结果通知协调者;
- 提交阶段(commit phase): 收到参与者的通知后,协调者再向参与者发出通知,根据反馈情况决定各参与者是否要提交还是回.
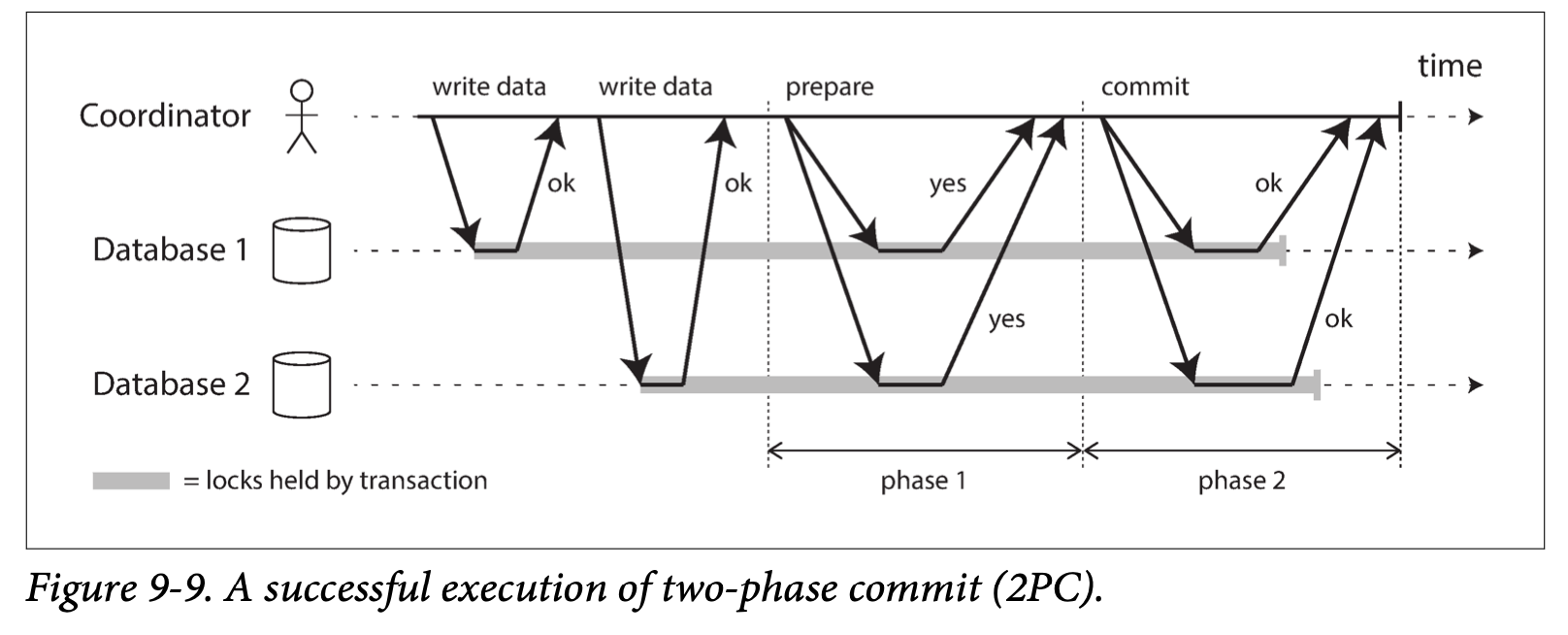
Much of the performance cost inherent in two-phase commit is due to the additional disk forcing (fsync) that is required for crash recovery, and the additional network round-trips.
Coordinator failure
2PC can become stuck waiting for the coordinator to recover.
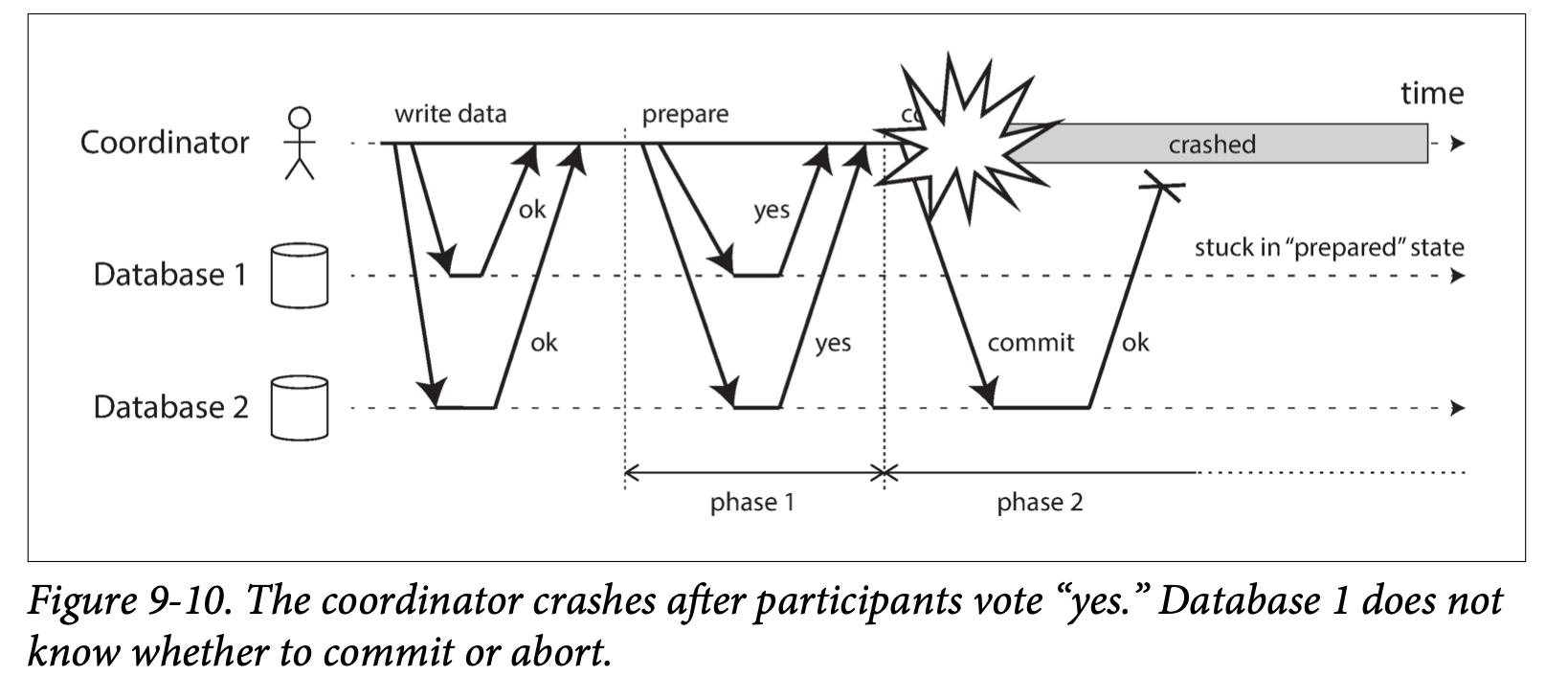
The only way 2PC can complete is by waiting for the coordinator to recover. This is why the coordinator must write its commit or abort decision to a transaction log on disk before sending commit or abort requests to participants:when the coordinator recovers, it determines the status of all in-doubt transactions by reading its transaction log. Any transactions that don’t have a commit record in the coordinator’s log are aborted. Thus, the commit point of 2PC comes down to a regular single-node atomic commit on the coordinator.
Distributed Transactions in Practice
Two types of distributed transactions are often conflated:
- Database-internal distributed transactions: work well as usual
- Heterogeneous distributed transactions: more challenge
Exactly-once message processing
Thus, by atomically committing the message and the side effects of its processing, we can ensure that the message is effectively processed exactly once, even if it required a few retries before it succeeded.
Such a distributed transaction is only possible if all systems affected by the transaction are able to use the same atomic commit protocol.
XA transaction
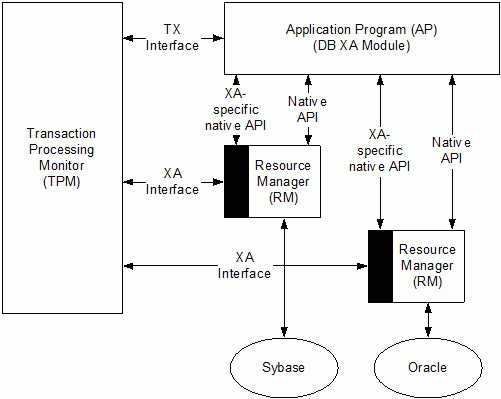
The transaction coordinator implements the XA API.
Holding locks while in doubt
The database cannot release those locks until the transaction commits or aborts, Therefore, when using two-phase commit, a transaction must hold onto the locks throughout the time it is in doubt.
This can cause large parts of your application to become unavailable until the in-doubt transaction is resolved.
Recovering from coordinator failure
Orphaned in-doubt transactions(如transaction log lost) cannot be resolved automatically, so they sit forever in the database, holding locks and blocking other transactions,只能通过管理员手动解决.
Many XA implementations have an emergency escape hatch called heuristic decisions: allowing a participant to unilaterally decide to abort or commit an in-doubt transaction without a definitive decision from the coordinator.
Limitations of distributed transactions
对于 XA transactions, the key realization is that the transaction coordinator is itself a kind of database (in which transaction outcomes are stored), and so it needs to be approached with the same care as any other important database.
Fault-Tolerant Consensus
思想: Everyone decides on the same outcome, and once you have decided, you cannot change your mind, a consensus algorithm must satisfy the following properties:
- Uniform agreement: No two nodes decide differently
- Integrity: No node decides twice.
- Validity
- Termination: the idea of
fault tolerance: 当有 node crash,也可以达成决策
Fault Tolerance:
- 为保证 termination,需要假设一旦 node crash, it suddenly disappears and
never comes back, 以避免无限等待 node recover. - 为保证 termination, 可以使用
quorum来允许部分 node crash. - 系统一定保证 safety properties,所以 Termination 不满足(如大量 node crash)也不会使系统做出错误的决策。
Consensus algorithm and total order broadcast
Consensu algorithm: vsr, paxos, raft, zab…
这些算法不直接使用上述 Consensus 模型,而是 they decide on a sequence of values, which makes them total order broadcast algorithms.
So, total order broadcast is equivalent to repeated rounds of consensus (each consensus decision corresponding to one message delivery).
例子: [https://www.cnblogs.com/j-well/p/7061091.html]
如何选举 leader:
Consensus algo 使用 leader,但是不保证 leader 唯一,所以需要解决选主问题:
当有多个 leader 时候,use a leader in some form or another, but they don’t guarantee that the leader is unique.
Node 为了确定自己是 leader,每次操作前需要举行投票确认自己的身份,因此 we have two rounds of voting: once to choose a leader, and a second time to vote on a leader’s proposal.
Consensus algorithms define a recovery process by which nodes can get into a consistent state after a new leader is elected, ensuring that the safety properties are always met.
Limitations of consensus
- 每次 proposal votes is a kind of synchronous replication.
影响性能 - 因为要进行 majority votes,所以对机器数量有要求(如:the remaining two out of three form a majority),如果发生 split brain,部分机器就会变得不可用。
- Most consensus algorithms assume a fixed set of nodes that participate in voting, which means that you can’t just add or remove nodes in the cluster.
- Consensus systems generally rely on timeouts to detect failed nodes. 在网络不好时候可能导致频繁的选主.
- Sometimes, consensus algorithms are particularly sensitive to network problems.
Membership and Coordination Services
ZooKeeper 使用场景:
- Linearizable atomic operations
- total order broadcast
- Failure detection
- Change notifications

